SamurAI Coding 2020-21 参加日記
3月19日に第9回 SamurAI Coding の決勝戦が行われた。私はチーム Monk1 の一員として参加させてもらった。期間が (他のコンテストと比較すると) 長めだったこともあり、すべて終わった今としては多少の悔しさと軽い達成感がある。せっかくなので、記憶が薄れないうちに参加記として残しておこうと思う。
なお、チームメイトの montplusa くんによる参加記もあるので是非どうぞ。私のこれはタイトルの通り日記なのであまりおもしろいものでもないと思う。彼の参加記は AI そのものや戦略の話に重点を置いているので有益だと思う。
そもそも戦略については多少のアイデアを加えたのみでほとんど彼に任せっきりだったので、なんと決勝ラウンドに提出された AI の仕様変更を完全には把握していない。でもこれは日記なのでそれはいい。私の視点から見た各時点でのチームの動向や空気感について振り返りながら記していきたい。
チームとしては3人で登録されている Monk1 ではあるが、リーダーは多忙で開発に全く参加できなかったので事実上2人 (私と montplusa くん) で開発を行っていた。その2人でスムーズに連携を取るために GitHub のプライベートリポジトリを利用していたので、そのコミット履歴を見ながら軌跡をたどり直してみようと思う。
SamurAI Coding とは
SamurAI Coding は情報処理学会が主催する国際人工知能プログラミングコンテストである。 (SamurAI Coding トップページより)
現在第9回となっており、2012年から毎年行われているようである。過去の大会のページもトップページ下部からリンクが張られていて様子を伺うことができる。私は今年初めて知ったのだが、残念ながら今年を区切りとして中止されるとのことである。
課題
今回の課題は宝探しである。
最大 12×12 のマス目のフィールドに埋蔵金が配置される。埋蔵金は始めから見えているものもあれば、地面に埋まって隠れているものもある。この埋蔵金を二人のプレイヤーが競って掘り合うというのがゲームの趣旨である。フィールドからすべての埋蔵金がなくなるか 100 ターンが経過するまで続けられ、終了時により多くの埋蔵金を掘り出していた方のプレイヤーが勝利となる。
各プレイヤーは 2 体のエージェント「侍」「犬」を操作することができる。このエージェントは明確に役割が分離されており、侍は埋蔵金を掘る役目を、犬は埋蔵金を探知する役割を与えられている。侍は穴を掘る操作すなわち埋蔵金を手に入れる操作と、すでにある穴を埋めるという動作をすることができる。犬は自分の周囲 8 マスにある隠れた埋蔵金を検知することができる。犬は埋蔵金の隠されたマスの上を通過するとその位置にある埋蔵金の量を周囲に通知し、味方の侍や敵の侍にもわかるようにする。
機動力も別々に設定されている。まず犬は上下左右と斜め、つまり周辺 8 方向へならどこへでも移動できる。侍は基本的には上下左右にしか動けないようになっているが、休憩 (REST) という行動をとった次のターンに限り斜め移動も可能となる。
さて、割と重要なルールに、異なるエージェント同士の行動が衝突する場合の扱いがある。細かい規定はルールに譲るとして、ざっくりといえば「エージェント同士がぶつかる場合は基本的には両者の行動を無効化する」である。これがあるので、実は犬を使って埋蔵金を探すのではなく犬を使って相手の侍を妨害する戦略が有効だったりする。
このゲームは去年行われたゲームに多少のルール調整が施されたものであるらしい。具体的な差異について詳しく調べてはいないが、少なくとも去年は侍の斜め移動が存在しなかった。しかし上の衝突時の無効化ルールがあったため、侍を角に追い込むことで犬が侍を行動不能にすることができたようである。今年のルール変更は主にその対策のためなのではないかと思われる。少なくとも侍が休憩後に斜め移動できるようになるルールと、犬と侍の斜め移動がクロスする場合は侍を優先するというルールが追加されている。これは今から思うと単純なようで奥の深いルール変更だったと感じている。
自分の役割
戦略ほとんど何も考えていないなら何をやっていたのかというと、ほとんどは周辺ツール作成とリファクタリングだった。
周辺ツールというのは、すなわち自動テスト・集計ツールである。戦略を試行錯誤するときに実際の戦績を簡単に確認できれば相当楽になる。敵と比較してどれほどの成績を上げるかということを自動でテストして集計するツールを作った。本当の敵の AI が召喚できればそれに越したことはないが、それはもちろん不可能なので、敵には前世代の AI やサンプルとして付属していた simplePlayer を起用した。
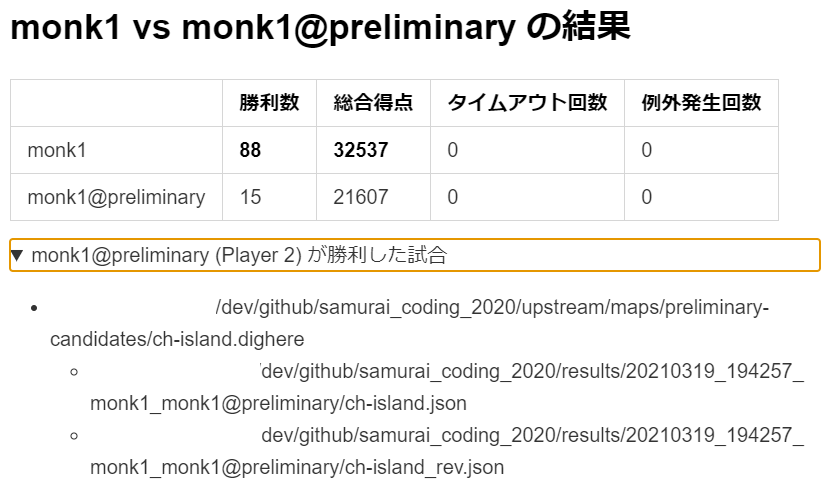
これは序盤から終盤まで AI の強さを見積もるのに非常に役立ったし、常に複数の世代と対戦させることで「直前の世代にだけ強い」 AI が作られることも防がれた。つまり「チョキ → グー → パー → チョキ → ・・・」のような無意味な循環を改善と勘違いする不毛な時間を回避できた。まあこれのせいで逆に平均的な強さの比較に終始してしまい、個別のマップでの最適な勝敗をおざなりにしてしまっただろうという反省もある。一応最新の AI が敗北した試合を表示する機能もあったのだが、試合数が多くて個別に十分詳しく敗北状況を調査できたとは言えない。
リファクタリングというのは、本当に言葉通りである。まず montplusa くんが作ってくれた原案 (それは monta_evaluate と呼ばれていた) に沿って、それと同じような動作をするコードをフルスクラッチで書き直す。これが現行の Monk1 の起源となる。以降、Pull Request が来るたびに少しずつリファクタリングしてマージしていた。 montplusa くんはベタッと数式を書いてしまうタイプの人なので、クラスや関数に分けることを冗長と感じたり、いちいち私が書き直したコードを読み直さなければならないことを面倒に感じたりしていたらしい。それでも割と長期間の開発にもかかわらず変なバグにはほとんど悩まされなかったので、一定の意味があったと思っている。

振り返り
さて、すでにだいぶ長くなってしまったが、ここからが本題である。順番に出来事を振り返っていこう。
第1回練習ラウンド (12/29 JST) まで
あれは12月の半ばのことであった。 Leader が SamurAI Coding を見つけてきて参加してみないかと言った。「年末年始、暇で時間あるし。」この台詞はあとになって全くの嘘であることがわかったが、とりあえずその時点では私も montplusa くんも信じていた。どうせ私に時間があったのは確かだし、 montplusa くんも乗り気だったと思う。かくして登録がなされた。その流れで GitHub にプライベートリポジトリを作り、 initial commit は12月16日のことだった。
私は普段なら Rust か C++ を使うのだけど、 montplusa くんがプログラミング初心者で Python を少し触った程度、 Leader は C か Python を使っているところしか見たことがない。 Bot Programming で Python を使うのは実行速度的に茨の道だろうと思いつつ、開発言語は Python に決まった。
Leader が「Python のサンプルプログラムが欲しいな。しばらく待てば追加されるかな」などと言っていたが、すでに C で書かれたサンプルがある以上はそんな期待もできないので、その日のうちにランダムな行動を起こす Python のサンプルプログラムを書いた。これは random_player と呼ばれている。ただ、この頃のゲームマネージャーとビジュアライザには多くのバグがあり、無効な手を選択すると高確率でビジュアライザが停止してしまうという問題があった。本来なら無効な手は自動で REST に置き換えるなどマネージャー側で弾かれるべきで、ビジュアライザに渡されてからエラーで停止するべきではない。このときはしばらくすれば直されるだろうと思ってとりあえず無効な移動をしないようにプログラムを書いたものの、そのためには画面外移動やエージェントに向かって移動するなどの無効な動作を手元で判定して弾かなければならず、そういう意味では「問題が起きないような最小のプログラム」を作るのは結構大変だったと思う。
さて、この段階ではまだ役割分担が明確ではなかった。 montplusa くんは random_player を派生させて AI を作り始めた。これは monta と呼ばれた。私は私で、やはり random_player をベースに、見えている埋蔵金を貪欲に掘りに行くようなプログラムを書き始めた。これは searching_player と呼ばれた。見えている埋蔵金をそこまでの距離で割った値を評価値として、評価値が最大な埋蔵金に向かっていって掘る。距離は dijkstra 法で最短ターン数を計算した。それだけだが、しかし、実は最終的に提出した侍も、評価の主軸はこれだった。自己紹介 PDF に shortest path, greedy と書いたのもまさにこの理由による。 AI の戦略に貢献したのはこれが最後だったかもしれない。この時点ですでに。
ここからしばらくの間、私は忙しくて作業をしていない。montplusa くんが AI の開発を進めていくことになる。
彼はまず見えていない埋蔵金に対応する AI を作りはじめた。基本的な考え方は簡単である。総合の埋蔵金量から見えている埋蔵金量を差し引いた分が隠れた埋蔵金の総量であるから、これを埋蔵金があるかもしれないマスに均等に分配していく。例えば埋蔵金の総量が 180 、見えている埋蔵金が 50 あるとするなら、見えていない埋蔵金は 130 ある。「あるかもしれない」マスが 10 マスあるならば、そのすべてのマスに 13 ずつ埋蔵金が存在していると仮定する。そうすれば単純な貪欲法のアルゴリズムが勝手に周囲をほってくれるし、見えている大きな埋蔵金があればそちらを優先して掘りに行ってくれる。ただまあ、実際には隠れた埋蔵金の分配は仮定でしかないし掘れば必ず得られるわけでもないので、「実際にそこにある 13 の埋蔵金」と「あるかもしれない仮定の 13 の埋蔵金」を完全に同一視するのは都合が悪い。そのため隠れた埋蔵金は適当な係数 (0.9 など) をかけて小さく見せている。評価値を利用する monta だから monta_evaluate と呼んでいた。以降しばらくはこれを書き換えながら進化していく。
見えない埋蔵金の処理が妥当になったところで、彼は犬を教育し始めた。というか、今の今まで犬は単におすわりしているだけの存在だった。犬についてどのように立ち振る舞うのが最適なのかはわかっていなかったからだ。そこでとりあえず犬には埋蔵金がない場所を適当に歩き回ってもらうことにした。犬が歩いた場所で犬が吠えなかった場所は全て埋蔵金が存在しない場所であることがわかる。つまり犬が歩けば歩くだけ侍が当てずっぽうで掘る必要のある位置をへらすことができたのだ。無論、その情報は敵にも渡ってしまうので効果は薄いだろうとはわかっていた。でもこの段階ではとりあえず歩いてくれればよかった。そう、なんとなく勘付かれるように、我々は割と犬に無頓着であった。この傾向は終盤まで続く。
この前後で去年の情報を持っていない我々が不利であることに気づき、去年の情報を探ったと思う。
まず、去年の公式サイトで決勝イベントの試合を確認した。このときに去年は斜め移動ができなかったことを知り、また、犬が侍を完全に移動できなくすることができることを知った。ここで犬が相手の侍を妨害するという戦略が相当有効であったことを知り、また、今年も一定以上有効だろうと考えた。掘り放題のステージでは、周辺をすべて貪欲に掘るのではなく、自分が移動する場所だけはあえて掘らずに残したまま効率よくずれて掘り進む様子を確認し、これも実装する必要があると考えた。
それ以外の大きい発見として、昨年度の優勝者であった ValGrowth さんが参加記を公開してくださっていることに気づいた。 (ありがとうございます!)
ルール変更があったとはいえ昨年度とほとんど同じゲームであり、この参加記は非常に参考になった。とはいえルールの変更はやはり結構効いていて、そのまま取り入れられたわけではない。例えば侍の動きが完封できなくなった今年のルールでは犬の重要度は去年よりは低下していると考え、犬を助ける動作は実装していない (実は実装したかったが、優先順位を大きく下げた結果実装できなかった) 。それでも、例えば、犬の側で侍の行動をまるごとシミュレーションして犬が自分の侍の邪魔をしない、同じ行動を連続で取らない、など、多くの点で参考にさせていただいた。
さて、そのような下調べを終え、彼は掘りの効率化に取り掛かった。このへんの実装は若干トリッキーで読みづらかったが、確か、二番目に良い評価値を与える位置 (次のターゲットになりそうな位置) を探し、最善の評価値を与える位置 (今から掘ろうとしている位置) を掘ることで次善の評価値を与える場所への道筋を塞いでしまうならば、その位置をほってしまう前に次善の位置に向かって移動する、といった実装だったはずだ。まあとにかくすごいコードが書かれていて、私は正しさを検証することは諦めた。
気づけば12月も27日になっていた。練習ラウンド前々日である。
大急ぎで翌日、彼は犬に敵を妨害させる動作を実装した。敵の侍からフィールドを眺め、各埋蔵金に至るまでの最短経路の道中に評価値を等分して置いていく。このようにして出来上がったマップでは、あるマスに置いてある値が大きければ大きいほど、そのマスは敵にとって価値があるマスだということになる。大きな埋蔵金に近づくためにはそのマスを通る必要があるからだ。だから犬はそんなマスへ移動して居座り、敵の侍の自由を奪う。妥当だとは思うが、ただ一つ問題があった。最短経路を一通りしか見ていないのである。この格子状のマップで。最短経路などいくらでもあるにも関わらず。ただ、我々はわかっていてその問題を無視した。練習ラウンド前に少し犬がマシな動きをするようになれば良いと思っていた。まあね、確かに時間もなかったし、一時的なことならば最善かもしれない。しかし、驚くべきことにというか、この犬の動きは決勝イベント前日まで変更されることはなかった。もはや犬が不憫に思える。ほんとになんで?
迎えた第1回練習ラウンドは、まだ参加人数が少なかったこともあってとりあえず全勝している。そこから考えると取り掛かり始めは相当早かったと思われる。
第2回練習ラウンド (1/13 JST) まで
さて、練習ラウンドを終えてから正月までは何もしなかった。次の行動は1月2日から始まっている。私が作業できるようになった代わりに montplusa くんが作業できなくなり、しばらくは私だけで作業する日々が続いた。
まず私は第1回練習ラウンドに提出された monta_evaluate を見て、ソースコードが私の手に終えるレベルではないことを知った。新年初の作業はまずこの monta_evaluate の動作をなるべく保ちながら書き直す作業だった。その成果が後に最終提出する AI の基盤となる monk1 である。 monk1 のコードは montplusa くんにはとても評判が悪かったが、押し切った。
この頃には「もっと手軽に戦略の成果を試したい」という声があり、また montplusa くんがしばらく作業できないというタイミングもちょうどよかったので、 monk1 を書きながらテストツールを作る作業も始めた。現在の AI と指定した敵とをまとめてすべての preliminary-candidates なマップの上で試して結果の集計をするプログラムである。ついでにそれを Pull Request と同時に実行する GitHub Actions も追加した。結局テストは手元で実行するほうが圧倒的に早かったのであまり役には立っていないが、逆に少し遅い CPU でタイムアウトしないかの参考程度の意味はあった。
テストツールが使えるようになると、想像以上にゲームマネージャーとビジュアライザの間に齟齬があったことに驚いた。それにはゲームマネージャーが正しいことも、ビジュアライザが正しいことも、どちらも間違っていることもあった。それらについては発見次第適宜大本の GitHub リポジトリ で報告させてもらったが、どれも素早く対応してもらえたことは助かった。ただ、テスト結果の信憑性が低い時期にはそれに依拠して AI を改善するのも若干不安があり、しばらくの間は開発を見送りつつバグを叩こうという話も起こっていた。このあたりで少し気持ちが離れてしまった部分はあったと思う。しばらくは monk1 に触れず、他の予定を消化したり CodinGame に明け暮れたりする日々が続いた。そう、 CodinGame の Bot Programming と SamurAI Coding はゲーム性も近く、しかし CodinGame はゲームが複数用意されていて面白そうなものを選ぶことができるとか、いつでも全世界の人に挑戦できて即座にフィードバックが返ってくるとか、そういう点で優れていた。
第2回練習ラウンドの期限が迫ってきて、流石に何かしらしなければならないだろうと言いながら、簡単に実装できる軽い修正を行った。
- 一度トライして妨害された埋蔵金はしばらくの間無視する。おそらくその埋蔵金は犬が守っているから取れないだろう。
- 味方の犬の下にある埋蔵金は無視しないようにする。通常エージェントの下にある埋蔵金は掘ることもできないが、味方の犬だけは避けてもらえば取ることができる。
- invalid move などで結果的に REST として扱われた REST は斜め移動可能として扱わない。そのような結果的な REST は斜め移動のためのエネルギーを充填しないことに気づいた。
- 同じ行動を繰り返さない。決定的アルゴリズムである以上、一度 stuck してしまえば一生 stuck する。それを避けるためには同じ行動を繰り返さない必要があり、一定期間同じマスで同じ方向に対して行動を取ることを禁じた。
ざっとそんな程度の本当に軽い修正だけ施して、第2回練習ラウンドに提出した。参加者も少しずつ増えていたが、まだ先にはじめた分だけリードがあり、このときもとりあえず全勝した。
予選 (2/2 JST) まで
当初の締め切りは1/26 JST だったが、一度マネージャーに大きなバグ修正があったためか、その後予選提出期限は一週間程度延長された。
第2回練習ラウンドの前後から、私は Python に限界を感じていた。と言うと Python に失礼なので正確に言い直そう。私は自分の能力で Python の性能を引き出すことに限界を感じていた。実のところやってみたいことはたくさんあった。例えば一手全探索もそうだ。でも Python での我々の AI の思考時間は限界で、全探索どころかもう一回 BFS を走らせるとタイムアウトしてしまうだろうという状況だった。
色々と考えた。明らかにグラフアルゴリズムが重たいから、そこだけ切り取って C++ で実装して Python からは呼ぶだけにしてみようか、とか。しかしそれは明らかにコンパイル作業の複雑さを増すし、バージョン違いでサーバーでだけ動かなかったりしかねない。それならばと思い、第2回練習ラウンドを終えた直後、私は monk1 をまるごとすべて C++ で書き直し始めた。そうすればそのまま書き直しただけでも実行時間は 1/10 ~ 1/20 程度にはなるだろう。しかし結局それは半分ほど書き直したところで montplusa くんに止められた。「やってもいいが、 C++ にされたら私はもう分からなくなるし書かない」と。
それを諦めたとて、元の monk1 を改善したわけでもなかった。なにもないのはということで、montplusa くんが休憩した次のターンにおいては最初の一手の斜め移動はターン数が1短縮されるという当たり前のことを正しく実装して PR を出した。それが 1/20 のことだった。私は彼にいくつか細かい点で修正を依頼したが彼には修正する時間がなく、結局締切直前 2/1 になって私が修正してマージした。それをそのまま提出した。
それでも予選は2位で通過した。しかも1位はあれだけ参考にした ValGrowth さんだったので、もうこれは仕方ないかあ、といった空気に支配されていた。
決勝イベント締め切り (3/9 JST) まで
このままでは勝てないことは分かっていた。そもそも予選 2 ~ 4 位の間に勝利数の差はない。得点差でわずかに競り勝っただけだ。間違いなく彼らはまた強化して参加するだろう。5 位以下だって全く油断ならない。しかしもうどう改善すべきかということもわからなくなっていた。これ以上の「直せたら良いこと」「できたらいいこと」には計算時間が必要だったが、もうほとんど捻出できない。思いつかないので気分転換に CodinGame をやって沼にはまった。
そもそも何が強いのかもわからなくなってきた。テスターで自分同士を戦わせると 0 対 0 で引き分ける。そして評価パラメータを一つ変えると、前の AI 対変更した AI が 45 対 55 、のように結果が出る。ではこの変更をした AI の方が元のより強いのかというと、この AI 、残りの 45 試合では負けているのである。決勝イベントはリーグ戦でも平均的勝率でもなく、選ばれた 1 つのマップですべてが決する。行った変更が 0 対 0 の状態から 0 対 10 になる、つまりただ勝ち試合だけが増えるだけという自明な改善はそうそうない。 8 割の勝率が出たとしても、残りの 2 割のマップが決勝戦で選ばれてしまうなら前の AI の方を提出しておく方が良かった。
ともかく、この期間中はどういう AI を出すのが良いのだろうねという話をずっとしていた記憶がある。最終的には我々はいくつかの改善をして、予選の AI に対して勝率 85% 、総合得点で 1.5 倍をとれる AI を提出した。でもこの AI は 15% のマップでは前の AI に負ける。マップによっては第1回の練習ラウンドに出した monta_evaluate にすら負ける。引き分けはほとんどない。これで出しても良いのか?
ちなみに、総合得点が 1.5 倍になったからくりは不遇だった犬にある。ラストスパートで犬の妨害に関する件の雑な方式をまるまる書き直し、より妥当な方式になった。その書き換えについては話には聞いているけれど説明できるほどではない。とりあえず妥当な方式になった。その結果旧 monk1 は思うように得点が取れなくなって、つまり相手を押し下げることで 1.5 倍になったということだ。
我々は結局この改善したように見える AI を提出するかどうか最後まで迷った。どこかのマップでは勝てるようになったが別のマップでは負けるようになる、それは単に AI が特定の特徴に特化しているだけで、偏りを大きくしているだけで、別に改善ではないのでは?
テスターは、我々が障害がなにもない取り放題ステージ (敵の犬が隔離されている、犬にとって歩きづらい etc.) に弱いことを明確に示していた。それは有り体に言えば我々の侍がビビリだということである。強化された侍の移動は犬が侍を完全に押さえつけることをよしとせず、逆に言えば侍は犬をかいくぐることができた。だから monk1 は犬と向かい合うと犬を避けるために犬を翻弄しようとするのだ。犬が粘着質なら効果があるだろうけど、そうでないなら時間の無駄でしかない。敵の犬が粘着質でも、自分の犬が同じくらい相手に粘着できていなければやっぱり負けてしまう。
でもまあ結局どうしようもないので出した。平均的には予選の monk1 よりは強い。
決勝イベントでは、我々の気持ちとしては残念ながら準々決勝で敗退することになった。問題となったマップは市松模様に 4x4 の穴と 4x4 の平地が重なっているマップだった。コマ落ちもあってしっかり見られなかったが、このようなマップは、犬がなまじ「移動できてしまう」にも関わらず基本的に遠回りを選ばされるマップであり、侍に追いつくことが難しい。ところが我々は犬に妨害されることを恐れ強気な行動はしない。特に REST を多用する。結果的に、何も考えず動いていれば振り切れたかもしれない犬を、しかし振り切れずにずっとじゃれ合い続けていたようだった。
我々のやり方についてと思うこと
色々と反省はある。少なくとも、モチベーションは失いすぎである。
少なくとも色の違う複数の AI を作ってみて、テスターの候補に追加しておくべきだった。
monk1 を進化させていった過程の各世代はテスターに含んでいたが、それはあくまでもある一本の系譜でしかない。別の系譜を持つ、例えば全探索する AI をいくつか追加しておけばよかった。
C++ に書き換えていた AI をとりあえず完成させておくべきだった。
実際には使わなかったとしてもそれを一つのテスターに加えることだってできたし、純粋に速度的アドバンテージを取れるのはその後の発展のためにも良かったと思う。 montplusa くんがかけないなら私が書けばよかった話でもある。
テスターが出力する統計的結果に頼りすぎた。
これについては仕方のない部分もある。テスターは 2000 試合以上を 30 分程度で終わらせてしまうが、我々が確認するのはそれほど短い時間では済まないので、敗北した試合が 10 件もあれば見るのは億劫になる。だが、それぞれの試合を一つずつ見れば不適当な動きは散見されたと思う。特に決勝前については、決勝戦がマップ一つで決まるということをもう少し意識するべきだった。
よかったこと
特に後半の動きが悪かったことは事実なので後半につれて書き様は重たくなってしまったが、別に今の気分がそれほど重たいわけではない。そもそも良かったことだって山ほどある。
まず Bot Programming の楽しみを思い出した。自分のプログラミングの原点はコンピュータを自分の意のままに動かすことだった。そして自分がやる仕事をコンピュータが高速に終わらせる様を見るのが好きだった。
CodinGame の Compete モードを知った。今まで CodinGame は Practice しかやったことがなかった。ビジュアライザがきれいだなと思う反面、敵もいないので、やっていることは普通の競プロと同じである。しかし Compete モードなら敵がいる。自分が書いた Bot が賢い動きをして敵を倒すというのは、自分の原点を思えばそれはもう楽しい体験だ。
久しぶりに複数人で楽しみながらプログラミングをした。基本的には普段は一人でプログラミングをすることが多いし、大規模なプログラムとなると個別の作業が組み込まれていくという印象が強くなる。今回のように一つの目標があって方針を相談しながら挑戦することは、それらとは違う楽しみがある。特に頭のいい人と組んで何か目的を達成するのは楽しい。
いろいろとある、本当に色々とある。
おわりに
冒頭にも書いたことだが、これだけ長い時間をかけてトライした大会は初めてだ。色々なことがあったし、それについてはもう十分話した。
大変良い体験をした。この大会に関わられたすべての方々に改めて感謝をして、この文章を閉じようと思う。
この日記をここまで読む人もいないとは思うが、もしそんな方がいたら、こんな長い独り言にお付き合いくださってありがとうございます。