HACK TO THE FUTURE 2023 予選 参加記
ふと思い立って久しぶりにヒューリスティックコンテストに参加してみたので記録しておく。来月には CodinGame もあることだし...。
というか、ヒューリスティックは成績にかかわらずなるべく参加記を残しておきたいという気持ちはある。実際、他のコンテストでも参加記を書こうという気持ち自体はあった。証拠もある。
単に書き切る前に時間が立ちすぎてしまって思い出せないから書き上げられなくなってしまったということなのだ。今回はそうならないように強い意志を持って書いている。
最終順位がでたのかどうかはよくわからないが、最終スコアっぽいなにかでソートすると 15 ページ目にいるので、およそ 300 位ということで大きく変わらないだろう。 (訂正) 最終スコアはまだ (2022/11/21 22:44) 出ていないらしい。まあ 300 位ぐらいやろ....。それにしても前後の得点は割とばらけているが、こういうものなのだろうか。経験が浅くてよくわからない。
今回は割と長期のコンテストではあったけれど、私が参加したのは事実上最後の土日のみ。とは言えもともとあまり集中力が続かない方なので、もっと前に始めていたからと言ってより良い結果になったとは思えない。
問題概要
0 から までの値をグラフ (最大 100 頂点) にエンコードせよ。その後そのうちのどれかのグラフを与えるので、逆にもとの値にデコードせよ。ただし、与えられる前にグラフの各辺は
の確率で反転する (あった辺はなくなり、なかった辺が増える) 上、頂点番号はシャッフルされる。なるべく小さいグラフにエンコードして大正解するほど得点が高い。
解法
至ってシンプルに入力の値に応じたサイズの完全グラフをドカンと作り、返ってきたグラフで次数がそれなりに高い頂点の数を数えるということをした。ちなみにグラフの中の部分グラフで完全なもののことをクリークと呼ぶらしいことは後で知った。それでいうと、パターンは入力値に応じたクリークと残りの孤立点、というような構成になっていた。
厳密なケース
が 0 のケースではミスがないので、100 通りのグラフを作っておくだけでいい感じにできる。ただ... 各種の対称性を加味してなお異なるグラフを正しく生成・判断できる自信がなかった上、全体のうち 1/40 でしか通用しない最適化をしても微妙かと思って後回しにしていた結果、サンプルと同じく単に辺の数を数える実装をそのまま残すことにした (
は
を収められる最小のものに変更しているが) 。この判断はあまりよくなかった。
エンコード
基本的には数字をそのまま頂点数として埋め込む。特に 2 進数にするなどの変換は行っていない。ただそのまま埋め込むと言っても 0 頂点の完全グラフを埋め込むというのはちょっと何言っているかわからない。そこで、とりあえずまず の入力値を +1 して
とした。これでまず一旦埋め込むことが不可能ではなくなった。
とは言っても、じゃあ 1 をエンコードして 1 頂点の完全グラフを埋め込みましょうと言っても、それはつまり単なる頂点なわけで、自己辺もないから識別できなくなってしまう。そこで頂点数に余裕があるときは、最低の頂点数 を
と
によって定めて、入力が
のときは実際には
頂点の完全グラフを生成することにした。例えば
のときは
としたらしい。こうすれば入力が 0 だったとしても +1 して
して、結局
頂点の完全グラフを作るということになる。これくらいなら十分大きいので判別できそうだ。
よし、じゃあ入力が 99 なら 頂点の完全グラフを...? 残念ながらそうはいかない。
が大きいときは諦めて、
は最大でも
ということになる。
ということはつまり のとき
なら 1 頂点の完全グラフを...? そうだよ。
いや、さすがに何も思わなかったわけではない。信じてほしい。挑戦したけど実を結ばなかったんだ。一応後でプレイ中の簡単な流れを記録しておくので、何を迷走していたのかはそれを見てほしい。
デコード
エンコード時点では一部のみがクリーク、残りが孤立点になっているはずなので、極端にたくさんの頂点とつながっている頂点と、全然どの頂点ともつながっていない頂点との両極端になっている。なので多少ノイズが入ったとしても次数は低いものと高いもので割りと極端に分かれるはず。真ん中あたりにいい感じのしきい値が取れればそれ以上の次数の頂点をクリークだと思えば、その集合のサイズから数字が復元できる。のだが、なかなかいい感じのしきい値が見つけられずに苦労した。
ちなみに厳密には、デコード時点では全ての頂点の次数をそのまま確認しているわけではない。グラフの中の各連結成分ごとに限定して、それぞれの中の次数をもとにクリークを検出している。これは後々、一つのグラフに複数のクリークを埋め込むことを考えるための布石を打っておいた。嘘だ。特に何も考えていなかった。クリークが一つの場合はたぶんもともとの次数で考えても良かったと思うが、当時は連結成分を求めるのが一番簡単だと思っていたようである。
問題のしきい値は、いい感じのしきい値が決められなかったので、「次数が割と極端に分かれるはず」という予想を信じて「次数を小さい順にソートしたときに最も大きく跳ね上がった値をしきい値とする」みたいに設定した。例えば次数が [2, 2, 3, 3, 9, 10, 10, ...] のようになっていたら、おそらく 9 以上の次数を持つ頂点がもともとのクリークだろうと推測することになる。
ちなみに連結成分ごとに考えるこのデコード方法では、ノイズによりクリークから完全に切断されてしまった頂点はクリークとして現れ得ない。まあでもそれは仕方ないと思うし完全グラフだからそれよりも切れにくい方法はないわけで、そう変化が偏って切れることはないと信じることにした。
で、クリークらしきものは連結成分ごとに得られることになる。最後の作業はその中から最も評価の高いものを選ぶこと。評価方法はシンプルに、クリークだと判断された頂点たちの次数の標準偏差による。本来ノイズがなければこれらはすべて一致するはずなので、標準偏差が小さければ小さいほどもっともらしいだろうと考えることにした。(ただ孤立点のところで「これが 1 頂点のクリークだ!標準偏差は 0!」と言われてしまうとたしかにとなってしまうので先に より小さいクリークは除く。)
スコア概要
最終的に提出していたやつの seed = 100 ~ 199 におけるスコアはこんな感じ。各値の意味はエスパーしてほしい。
0028.txt (31, 0.0) ... N = 9, E = 0, score = 111111111 0067.txt (44, 0.0) ... N = 10, E = 0, score = 100000000 0062.txt (10, 0.06) ... N = 24, E = 0, score = 41666667 0030.txt (12, 0.07) ... N = 26, E = 0, score = 38461538 0057.txt (16, 0.04) ... N = 26, E = 0, score = 38461538 0082.txt (13, 0.06) ... N = 27, E = 0, score = 37037037 0029.txt (21, 0.03) ... N = 31, E = 0, score = 32258065 0059.txt (16, 0.11) ... N = 32, E = 0, score = 31250000 0022.txt (12, 0.11) ... N = 24, E = 3, score = 30375000 0051.txt (24, 0.04) ... N = 34, E = 0, score = 29411765 0072.txt (23, 0.07) ... N = 37, E = 0, score = 27027027 0098.txt (28, 0.03) ... N = 38, E = 0, score = 26315789 0006.txt (32, 0.02) ... N = 42, E = 0, score = 23809524 0061.txt (24, 0.06) ... N = 38, E = 1, score = 23684211 0097.txt (31, 0.06) ... N = 45, E = 0, score = 22222222 0041.txt (33, 0.07) ... N = 47, E = 0, score = 21276596 0080.txt (38, 0.03) ... N = 48, E = 0, score = 20833333 0050.txt (35, 0.05) ... N = 49, E = 0, score = 20408163 0086.txt (29, 0.16) ... N = 58, E = 0, score = 17241379 0063.txt (30, 0.15) ... N = 60, E = 0, score = 16666667 0038.txt (48, 0.07) ... N = 62, E = 0, score = 16129032 0085.txt (59, 0.04) ... N = 69, E = 0, score = 14492754 0076.txt (51, 0.07) ... N = 65, E = 1, score = 13846154 0096.txt (38, 0.15) ... N = 76, E = 0, score = 13157895 0077.txt (39, 0.19) ... N = 78, E = 1, score = 11538462 0036.txt (81, 0.04) ... N = 91, E = 0, score = 10989011 0019.txt (47, 0.14) ... N = 94, E = 0, score = 10638298 0043.txt (57, 0.08) ... N = 71, E = 3, score = 10267606 0092.txt (36, 0.22) ... N = 100, E = 0, score = 10000000 0044.txt (22, 0.21) ... N = 100, E = 0, score = 10000000 0001.txt (42, 0.22) ... N = 100, E = 0, score = 10000000 0027.txt (62, 0.12) ... N = 100, E = 0, score = 10000000 0060.txt (53, 0.18) ... N = 100, E = 0, score = 10000000 0081.txt (33, 0.21) ... N = 100, E = 0, score = 10000000 0033.txt (66, 0.16) ... N = 100, E = 0, score = 10000000 0016.txt (71, 0.11) ... N = 100, E = 0, score = 10000000 0045.txt (50, 0.1) ... N = 100, E = 0, score = 10000000 0064.txt (72, 0.15) ... N = 100, E = 1, score = 9000000 0069.txt (32, 0.27) ... N = 100, E = 1, score = 9000000 0091.txt (27, 0.28) ... N = 100, E = 1, score = 9000000 0011.txt (59, 0.08) ... N = 73, E = 4, score = 8987671 0049.txt (85, 0.04) ... N = 95, E = 2, score = 8526316 0099.txt (42, 0.27) ... N = 100, E = 2, score = 8100000 0012.txt (79, 0.13) ... N = 100, E = 2, score = 8100000 0052.txt (76, 0.06) ... N = 90, E = 3, score = 8100000 0058.txt (47, 0.26) ... N = 100, E = 3, score = 7290000 0042.txt (42, 0.27) ... N = 100, E = 3, score = 7290000 0039.txt (38, 0.27) ... N = 100, E = 3, score = 7290000 0009.txt (80, 0.01) ... N = 86, E = 5, score = 6866163 0054.txt (93, 0.03) ... N = 100, E = 4, score = 6561000 0014.txt (47, 0.25) ... N = 100, E = 4, score = 6561000 0048.txt (79, 0.08) ... N = 93, E = 5, score = 6349355 0018.txt (57, 0.23) ... N = 100, E = 5, score = 5904900 0078.txt (43, 0.24) ... N = 100, E = 5, score = 5904900 0023.txt (16, 0.32) ... N = 100, E = 5, score = 5904900 0035.txt (94, 0.04) ... N = 100, E = 5, score = 5904900 0093.txt (68, 0.09) ... N = 82, E = 8, score = 5249600 0032.txt (19, 0.33) ... N = 100, E = 7, score = 4782969 0084.txt (84, 0.19) ... N = 100, E = 12, score = 2824295 0000.txt (92, 0.08) ... N = 100, E = 13, score = 2541866 0047.txt (91, 0.12) ... N = 100, E = 15, score = 2058911 0031.txt (76, 0.18) ... N = 100, E = 15, score = 2058911 0046.txt (98, 0.07) ... N = 100, E = 15, score = 2058911 0065.txt (53, 0.28) ... N = 100, E = 16, score = 1853020 0020.txt (56, 0.27) ... N = 100, E = 17, score = 1667718 0071.txt (31, 0.32) ... N = 100, E = 18, score = 1500946 0004.txt (96, 0.1) ... N = 100, E = 18, score = 1500946 0068.txt (96, 0.1) ... N = 100, E = 19, score = 1350852 0007.txt (86, 0.14) ... N = 100, E = 20, score = 1215767 0013.txt (84, 0.16) ... N = 100, E = 22, score = 984771 0079.txt (49, 0.31) ... N = 100, E = 22, score = 984771 0053.txt (17, 0.35) ... N = 100, E = 24, score = 797664 0024.txt (92, 0.17) ... N = 100, E = 25, score = 717898 0015.txt (44, 0.32) ... N = 100, E = 26, score = 646108 0040.txt (28, 0.34) ... N = 100, E = 27, score = 581497 0034.txt (90, 0.19) ... N = 100, E = 28, score = 523348 0037.txt (98, 0.19) ... N = 100, E = 32, score = 343368 0090.txt (66, 0.27) ... N = 100, E = 33, score = 309032 0073.txt (44, 0.32) ... N = 100, E = 36, score = 225284 0087.txt (84, 0.26) ... N = 100, E = 39, score = 164232 0066.txt (94, 0.26) ... N = 100, E = 44, score = 96977 0088.txt (29, 0.36) ... N = 100, E = 50, score = 51538 0074.txt (78, 0.29) ... N = 100, E = 50, score = 51538 0025.txt (58, 0.34) ... N = 100, E = 52, score = 41746 0055.txt (78, 0.31) ... N = 100, E = 53, score = 37571 0070.txt (92, 0.3) ... N = 100, E = 58, score = 22185 0094.txt (39, 0.36) ... N = 100, E = 59, score = 19967 0095.txt (60, 0.35) ... N = 100, E = 69, score = 6962 0008.txt (70, 0.35) ... N = 100, E = 71, score = 5639 0002.txt (92, 0.32) ... N = 100, E = 74, score = 4111 0089.txt (17, 0.4) ... N = 100, E = 75, score = 3700 0010.txt (48, 0.37) ... N = 100, E = 76, score = 3330 0056.txt (30, 0.39) ... N = 100, E = 80, score = 2185 0021.txt (83, 0.35) ... N = 100, E = 81, score = 1966 0005.txt (83, 0.37) ... N = 100, E = 85, score = 1290 0026.txt (29, 0.4) ... N = 100, E = 88, score = 940 0083.txt (68, 0.37) ... N = 100, E = 91, score = 686 0003.txt (56, 0.4) ... N = 100, E = 93, score = 555 0075.txt (94, 0.4) ... N = 100, E = 100, score = 266 0017.txt (100, 0.33) ... N = 100, E = 100, score = 266 sum: 1078514052
スコア順に並べているが、誤答率を見ると、やはり が大きいケースと
が大きいケースに弱い。(その傾向自体は人類全員同じだと思っているが...)
結局 を大きく取って安定感を増しているだけなので十分下駄を履かせることができないと微妙になる。一部
くらいのケースでも誤答してしまっているのは
が割と大きいのに
をケチりすぎているということで、普通にもったいない。ただこのあたりの数字は温かみのある手動調整なので十分試せなかった。
ちなみに、当時適当に一番下の絶対スコア合計値でなんとなく評価していたのだが、これだと難関ケースを過小評価することになってしまうのをどうすればよいかは最後までよくわからなかった。終わってから、バケモノみたいな人たち (※褒め言葉) が難関ケースで高得点を取ってしまえば自分の解法などそこでは塵になってしまうので、そこの微改善は相対スコア的にはそんなに変わらないみたいなことを言われて鵜呑みにした。よくわかっていない。何れにせよ結局解きやすいところで大きく離されないようにすることは大切そうだった。
あと、なんですか でお祈りって。言われてみれば
は絶対にゼロにはならないから、どうせ全ミスするなら頂点数が少ないほうが有利というのは気づきたかった。一番下のスコア 266 とか見てるとやっておけばよかったな...。どれくらい効果があったかはわからないけど。
コンテスト中の流れ
サンプル解提出
問題を読んで、そもそも頂点がシャッフルされる場合にどうやって情報を伝えればいいんや... と本当によくわからなかった。サンプルが辺の数を数えるという実装だったわけだが、これがなければやるべきことの発想が数時間遅れていたんじゃないかと思う。サンプル解で既に天才だと思った。
とりあえずコピー&ペーストで Python のサンプルを投げたあと、Rust で書き直して再提出。全く同一の得点が得られたことを確認した。
サンプル解では が 0 でないときはほとんど正解せず、0 のときは
によっては逆に頂点の数が必要以上に多いので、とりあえず必要最低限の頂点数だけ使うという自明な改善をやった。実のところ
の場合は最終提出でもこれである。
最初の追加実装
流石に辺の数は変化に脆弱すぎるのでもう少し多少の変化では崩れないようにしたいと思った。この時点で、デコード時にクエリとして与えられたグラフが元のグラフのどのグラフであるかを判別するという方針は取らないことにした。この実装は上位を目指すなら絶対に必要だろうとは思ったが、そもそも対称性を考慮して相異なるグラフたちを生成する方法が全く分からなかったし、作ったとしてももとの頂点順序をいい感じに復元する方法も思いつかなかったし、ロスがあったときにどのグラフと「近い」と判断するべきかの方法も全く思いつかなかった。こういうときになんとなく強そうで実装を始めてもうまくいかないことが経験則により知られているので避けた。なんとなく強そうで改善できる方々、すなわちいろいろな要素の中でどの要素が結果により寄与するか (センスあるいは経験あるいは両方で) 判断できる人たちはすごいと思う。
もとのグラフとのマッチングをしないなら、もとのグラフは単なる模様ではなく、それ自体が何かしら意味を持つようにしなければいけない。その時に思いついたのが 2 つ。
- 頂点を円形に並べて隣同士で手をつなぐ。シャッフルされても円は復元できる。そこで対角線のパターンを使って意味を与える
- ある程度のサイズのクリークを作成しておき、孤立点からそのクリークの全頂点に向かって辺を張る。そういう孤立点の数をデータとする。
このうち、実装が簡単そうな 2 をまずは選択。 実装し、少なくともサンプルよりはだいぶ強いスコアが出た。ま、サンプルは が 0 じゃないときはほぼ誤答だから...。
それなりの精度を出すためには「ある程度のサイズ」が くらい要るということがわかった。すると全体が
頂点必要になるので、
で頂点数が足りなくなる。この時点では
が大きいケースでは 1 の方法でなんとかしようと思っていたので一旦諦めていた。そして 1 についてはある程度実装した段階で、よく考えたら思った以上に対称性が高くない?となってしまい、対角線のパターンが想像以上に少ないことに気づいた。頂点数を増やすのにも限界があるし、冷静に考えたら対角線のパターンを列挙できる人間ならグラフの列挙くらいできるはずだろう。対偶を取って諦めた。そもそも対角線も (多重化していたが) だいぶ対障害性が低そうだったし。
最終提出解
2 の実装はエンコードしたい値に対して 2 倍量の頂点が必要なのがどうもまずい。比率をあれこれ悪あがきしているうちに、そもそも最初からクリークを数えればよいのでは?という発想に至った。むしろなぜこちらが先に出て来ない?
ともかく、それならどれくらい下駄を履かせるかにもよるけれど、少なくとも が小さければ 2 倍もいらないだろう。で、生まれたのが最終提出ってわけ。
辺の数を数えてみたり
ここでシンプルな実装として辺の数を多重化して数えるやつも一応、やってみた。グラフは入力×多重度分の辺をセットしておき、戻ってきたグラフの辺の数を数えて期待値が最も近い最初のグラフを返すというやつ。
が大きくて
が小さいときに代替で使えるといいなと思ったが、結局そういうケースですら最終提出に正確性が劣ったため採用できなかった。
やりたかったもの
最終提出解にしても が大きいと履かせるべき下駄が用意できないという問題がある。このためにはどうにかして情報効率を上げたい。2 進数でも 3 進数でも良いけれど、あまりグラフが細かいコンポーネントに分かれると復元が難しくなりそうだし、そもそも桁を判別するのも難しくなる。できても 2つだろう。
ならばと「十の位+一の位」というエンコーディングをすることにした。それぞれの位は 0 ~ 9 の数字である。これを 1 ~ 10 にし、従来の方法でエンコードする。ただ、これでは位が判別できない。そこで十の位は 2 倍した偶数、一の位は 2 倍した奇数としてエンコードすることにした。例えば入力が 54 だったとしよう。これは 「10」「9」とエンコードする。逆にデコードしたときにこの 2 つが出てきたときは 54 と復元できる。10 と 9 のエンコードは従来の方法によった、つまり
を足して 10 + B と 9 + B 頂点のクリークとした。問題は十分な精度で取れるかどうかだが、実際に単一クリークの場合は
が小さければそれなりの正答率があるわけなので、要するに 100 連続正解を 200 連続正解にすればよいということになる。少なくとも現状
が大きいときの小さい値の正答率が塵であることを思えば改善になるのではないかと思った。
が大きいケースでは
も減るし。天才では?
だが、まあ、シンプルに考えて、シャッフル+ノイズの後、10 + B と 9 + B が別のクリークであると認識するのが難しい、という、至極当たり前のことに気づかなかったあたりはいつものクオリティである。次数のしきい値が 8 あたりになってしまったとき、2つのクリークがノイズによってたまたま連結になってしまったら (たまたまどころではなく大抵はそうなるわけだが) 合わせて 19 + 2B の巨大なクリークとして発見される。これを分離するのは非常に難しい。総じて が小さいときでも半数程度しか正答できないような状態だった。
これは次数しか見ないとどうやっても倒せないので最小カット的なことを考えることにした。エンコード方法に対して巨大すぎるクリークが発見されたときはそれを最小カットによって 2 つに分割する。これは実装を書き上げた後、バグっていることを確認してコンテスト時間が終了となった。うまく言っていたらどれくらいだったんだろう。言ってもそこまでではない気がする。
2 つのクリーク数がすごく近いのが問題なわけで、10 の位は +30 頂点するみたいなやり方にしておけば実は良かった可能性もあるな...。
反省
まずは のときの実装をサボったこと。
ここはしっかり詰めるべきだった。全体の得点的に放置するのが不利になるというところもあるし、詰める途中でグラフ同型... とは言わなくても、次数列などもう少し上に向かっていける着想が得られた可能性が高そうだったから。少なくとも問題の理解度は上がったはず。
また、クリークを分離するときにずっとしきい値のことばかり考えていたこと。
それこそこういうところで焼きなましが生きたのかもしれない。わからないけれど、どう分割するのが一番すわりがいいかみたいな最適化をやればより精度が出せたかもしれない。少なくともビジュアライザでノイズ後のグラフを見る限り「これくらいなら復元できるだろう」みたいなときでも取りこぼしてることが多かった。もちろん私が見ているのはあくまで頂点シャッフル前だからというのはあるけれど。このへんはこれから経験を積んでいきたいところ。
最後、相変わらずルールの理解が甘いこと。
お祈りに気づけなかったこともそうだけど、
をへらすことと正答率を上げることの (具体的な数字での) 優先順位、相対評価であることを前提としてどこを上げるのが相対スコアの向上につながるのか、といったことをもっと詰めるべきだった。パソコンが好きなのでなにか思うことがあったらすぐパソコンカタカタしてしまうけれど、何であれ、一旦落ち着いて考えをまとめてから始めたほうがいいことのほうが多い。
おわりに
やっぱり自分にプログラミングは難しいけど、コンテストは楽しい。この問題は段階に応じた手の届きそうな解法がいくつもあってとてもおもしろかった。サンプル解が重要な気づきを与えてくれる上に改善の余地があって、そこから一段ずつ上っていけるところが楽しかった。少なくともプレイ中の発想と最適化のバランスは個人的にちょうどよかった。長期コンテストは参加できるタイミングがたくさんあるので、なるべく積極的に参加していきたい。すべての時間をコンテストに費やさないといけないわけではないしね。
SamurAI Coding 2020-21 参加日記
3月19日に第9回 SamurAI Coding の決勝戦が行われた。私はチーム Monk1 の一員として参加させてもらった。期間が (他のコンテストと比較すると) 長めだったこともあり、すべて終わった今としては多少の悔しさと軽い達成感がある。せっかくなので、記憶が薄れないうちに参加記として残しておこうと思う。
なお、チームメイトの montplusa くんによる参加記もあるので是非どうぞ。私のこれはタイトルの通り日記なのであまりおもしろいものでもないと思う。彼の参加記は AI そのものや戦略の話に重点を置いているので有益だと思う。
そもそも戦略については多少のアイデアを加えたのみでほとんど彼に任せっきりだったので、なんと決勝ラウンドに提出された AI の仕様変更を完全には把握していない。でもこれは日記なのでそれはいい。私の視点から見た各時点でのチームの動向や空気感について振り返りながら記していきたい。
チームとしては3人で登録されている Monk1 ではあるが、リーダーは多忙で開発に全く参加できなかったので事実上2人 (私と montplusa くん) で開発を行っていた。その2人でスムーズに連携を取るために GitHub のプライベートリポジトリを利用していたので、そのコミット履歴を見ながら軌跡をたどり直してみようと思う。
SamurAI Coding とは
SamurAI Coding は情報処理学会が主催する国際人工知能プログラミングコンテストである。 (SamurAI Coding トップページより)
現在第9回となっており、2012年から毎年行われているようである。過去の大会のページもトップページ下部からリンクが張られていて様子を伺うことができる。私は今年初めて知ったのだが、残念ながら今年を区切りとして中止されるとのことである。
課題
今回の課題は宝探しである。
最大 12×12 のマス目のフィールドに埋蔵金が配置される。埋蔵金は始めから見えているものもあれば、地面に埋まって隠れているものもある。この埋蔵金を二人のプレイヤーが競って掘り合うというのがゲームの趣旨である。フィールドからすべての埋蔵金がなくなるか 100 ターンが経過するまで続けられ、終了時により多くの埋蔵金を掘り出していた方のプレイヤーが勝利となる。
各プレイヤーは 2 体のエージェント「侍」「犬」を操作することができる。このエージェントは明確に役割が分離されており、侍は埋蔵金を掘る役目を、犬は埋蔵金を探知する役割を与えられている。侍は穴を掘る操作すなわち埋蔵金を手に入れる操作と、すでにある穴を埋めるという動作をすることができる。犬は自分の周囲 8 マスにある隠れた埋蔵金を検知することができる。犬は埋蔵金の隠されたマスの上を通過するとその位置にある埋蔵金の量を周囲に通知し、味方の侍や敵の侍にもわかるようにする。
機動力も別々に設定されている。まず犬は上下左右と斜め、つまり周辺 8 方向へならどこへでも移動できる。侍は基本的には上下左右にしか動けないようになっているが、休憩 (REST) という行動をとった次のターンに限り斜め移動も可能となる。
さて、割と重要なルールに、異なるエージェント同士の行動が衝突する場合の扱いがある。細かい規定はルールに譲るとして、ざっくりといえば「エージェント同士がぶつかる場合は基本的には両者の行動を無効化する」である。これがあるので、実は犬を使って埋蔵金を探すのではなく犬を使って相手の侍を妨害する戦略が有効だったりする。
このゲームは去年行われたゲームに多少のルール調整が施されたものであるらしい。具体的な差異について詳しく調べてはいないが、少なくとも去年は侍の斜め移動が存在しなかった。しかし上の衝突時の無効化ルールがあったため、侍を角に追い込むことで犬が侍を行動不能にすることができたようである。今年のルール変更は主にその対策のためなのではないかと思われる。少なくとも侍が休憩後に斜め移動できるようになるルールと、犬と侍の斜め移動がクロスする場合は侍を優先するというルールが追加されている。これは今から思うと単純なようで奥の深いルール変更だったと感じている。
自分の役割
戦略ほとんど何も考えていないなら何をやっていたのかというと、ほとんどは周辺ツール作成とリファクタリングだった。
周辺ツールというのは、すなわち自動テスト・集計ツールである。戦略を試行錯誤するときに実際の戦績を簡単に確認できれば相当楽になる。敵と比較してどれほどの成績を上げるかということを自動でテストして集計するツールを作った。本当の敵の AI が召喚できればそれに越したことはないが、それはもちろん不可能なので、敵には前世代の AI やサンプルとして付属していた simplePlayer を起用した。
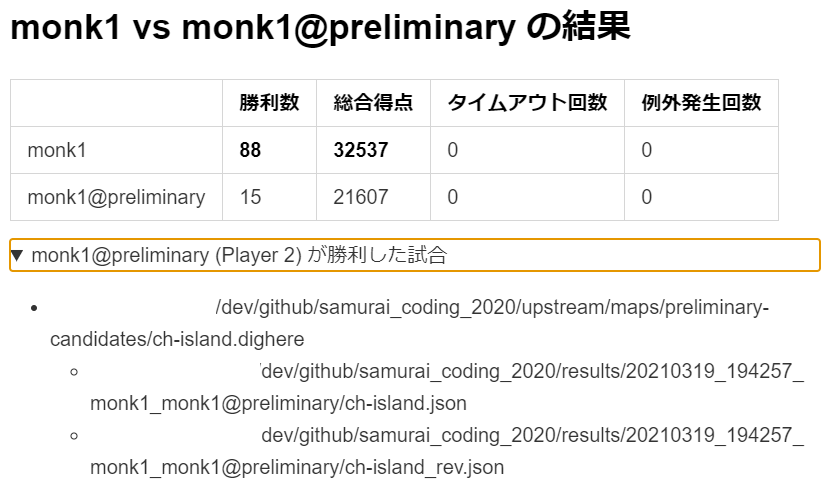
これは序盤から終盤まで AI の強さを見積もるのに非常に役立ったし、常に複数の世代と対戦させることで「直前の世代にだけ強い」 AI が作られることも防がれた。つまり「チョキ → グー → パー → チョキ → ・・・」のような無意味な循環を改善と勘違いする不毛な時間を回避できた。まあこれのせいで逆に平均的な強さの比較に終始してしまい、個別のマップでの最適な勝敗をおざなりにしてしまっただろうという反省もある。一応最新の AI が敗北した試合を表示する機能もあったのだが、試合数が多くて個別に十分詳しく敗北状況を調査できたとは言えない。
リファクタリングというのは、本当に言葉通りである。まず montplusa くんが作ってくれた原案 (それは monta_evaluate と呼ばれていた) に沿って、それと同じような動作をするコードをフルスクラッチで書き直す。これが現行の Monk1 の起源となる。以降、Pull Request が来るたびに少しずつリファクタリングしてマージしていた。 montplusa くんはベタッと数式を書いてしまうタイプの人なので、クラスや関数に分けることを冗長と感じたり、いちいち私が書き直したコードを読み直さなければならないことを面倒に感じたりしていたらしい。それでも割と長期間の開発にもかかわらず変なバグにはほとんど悩まされなかったので、一定の意味があったと思っている。

振り返り
さて、すでにだいぶ長くなってしまったが、ここからが本題である。順番に出来事を振り返っていこう。
第1回練習ラウンド (12/29 JST) まで
あれは12月の半ばのことであった。 Leader が SamurAI Coding を見つけてきて参加してみないかと言った。「年末年始、暇で時間あるし。」この台詞はあとになって全くの嘘であることがわかったが、とりあえずその時点では私も montplusa くんも信じていた。どうせ私に時間があったのは確かだし、 montplusa くんも乗り気だったと思う。かくして登録がなされた。その流れで GitHub にプライベートリポジトリを作り、 initial commit は12月16日のことだった。
私は普段なら Rust か C++ を使うのだけど、 montplusa くんがプログラミング初心者で Python を少し触った程度、 Leader は C か Python を使っているところしか見たことがない。 Bot Programming で Python を使うのは実行速度的に茨の道だろうと思いつつ、開発言語は Python に決まった。
Leader が「Python のサンプルプログラムが欲しいな。しばらく待てば追加されるかな」などと言っていたが、すでに C で書かれたサンプルがある以上はそんな期待もできないので、その日のうちにランダムな行動を起こす Python のサンプルプログラムを書いた。これは random_player と呼ばれている。ただ、この頃のゲームマネージャーとビジュアライザには多くのバグがあり、無効な手を選択すると高確率でビジュアライザが停止してしまうという問題があった。本来なら無効な手は自動で REST に置き換えるなどマネージャー側で弾かれるべきで、ビジュアライザに渡されてからエラーで停止するべきではない。このときはしばらくすれば直されるだろうと思ってとりあえず無効な移動をしないようにプログラムを書いたものの、そのためには画面外移動やエージェントに向かって移動するなどの無効な動作を手元で判定して弾かなければならず、そういう意味では「問題が起きないような最小のプログラム」を作るのは結構大変だったと思う。
さて、この段階ではまだ役割分担が明確ではなかった。 montplusa くんは random_player を派生させて AI を作り始めた。これは monta と呼ばれた。私は私で、やはり random_player をベースに、見えている埋蔵金を貪欲に掘りに行くようなプログラムを書き始めた。これは searching_player と呼ばれた。見えている埋蔵金をそこまでの距離で割った値を評価値として、評価値が最大な埋蔵金に向かっていって掘る。距離は dijkstra 法で最短ターン数を計算した。それだけだが、しかし、実は最終的に提出した侍も、評価の主軸はこれだった。自己紹介 PDF に shortest path, greedy と書いたのもまさにこの理由による。 AI の戦略に貢献したのはこれが最後だったかもしれない。この時点ですでに。
ここからしばらくの間、私は忙しくて作業をしていない。montplusa くんが AI の開発を進めていくことになる。
彼はまず見えていない埋蔵金に対応する AI を作りはじめた。基本的な考え方は簡単である。総合の埋蔵金量から見えている埋蔵金量を差し引いた分が隠れた埋蔵金の総量であるから、これを埋蔵金があるかもしれないマスに均等に分配していく。例えば埋蔵金の総量が 180 、見えている埋蔵金が 50 あるとするなら、見えていない埋蔵金は 130 ある。「あるかもしれない」マスが 10 マスあるならば、そのすべてのマスに 13 ずつ埋蔵金が存在していると仮定する。そうすれば単純な貪欲法のアルゴリズムが勝手に周囲をほってくれるし、見えている大きな埋蔵金があればそちらを優先して掘りに行ってくれる。ただまあ、実際には隠れた埋蔵金の分配は仮定でしかないし掘れば必ず得られるわけでもないので、「実際にそこにある 13 の埋蔵金」と「あるかもしれない仮定の 13 の埋蔵金」を完全に同一視するのは都合が悪い。そのため隠れた埋蔵金は適当な係数 (0.9 など) をかけて小さく見せている。評価値を利用する monta だから monta_evaluate と呼んでいた。以降しばらくはこれを書き換えながら進化していく。
見えない埋蔵金の処理が妥当になったところで、彼は犬を教育し始めた。というか、今の今まで犬は単におすわりしているだけの存在だった。犬についてどのように立ち振る舞うのが最適なのかはわかっていなかったからだ。そこでとりあえず犬には埋蔵金がない場所を適当に歩き回ってもらうことにした。犬が歩いた場所で犬が吠えなかった場所は全て埋蔵金が存在しない場所であることがわかる。つまり犬が歩けば歩くだけ侍が当てずっぽうで掘る必要のある位置をへらすことができたのだ。無論、その情報は敵にも渡ってしまうので効果は薄いだろうとはわかっていた。でもこの段階ではとりあえず歩いてくれればよかった。そう、なんとなく勘付かれるように、我々は割と犬に無頓着であった。この傾向は終盤まで続く。
この前後で去年の情報を持っていない我々が不利であることに気づき、去年の情報を探ったと思う。
まず、去年の公式サイトで決勝イベントの試合を確認した。このときに去年は斜め移動ができなかったことを知り、また、犬が侍を完全に移動できなくすることができることを知った。ここで犬が相手の侍を妨害するという戦略が相当有効であったことを知り、また、今年も一定以上有効だろうと考えた。掘り放題のステージでは、周辺をすべて貪欲に掘るのではなく、自分が移動する場所だけはあえて掘らずに残したまま効率よくずれて掘り進む様子を確認し、これも実装する必要があると考えた。
それ以外の大きい発見として、昨年度の優勝者であった ValGrowth さんが参加記を公開してくださっていることに気づいた。 (ありがとうございます!)
ルール変更があったとはいえ昨年度とほとんど同じゲームであり、この参加記は非常に参考になった。とはいえルールの変更はやはり結構効いていて、そのまま取り入れられたわけではない。例えば侍の動きが完封できなくなった今年のルールでは犬の重要度は去年よりは低下していると考え、犬を助ける動作は実装していない (実は実装したかったが、優先順位を大きく下げた結果実装できなかった) 。それでも、例えば、犬の側で侍の行動をまるごとシミュレーションして犬が自分の侍の邪魔をしない、同じ行動を連続で取らない、など、多くの点で参考にさせていただいた。
さて、そのような下調べを終え、彼は掘りの効率化に取り掛かった。このへんの実装は若干トリッキーで読みづらかったが、確か、二番目に良い評価値を与える位置 (次のターゲットになりそうな位置) を探し、最善の評価値を与える位置 (今から掘ろうとしている位置) を掘ることで次善の評価値を与える場所への道筋を塞いでしまうならば、その位置をほってしまう前に次善の位置に向かって移動する、といった実装だったはずだ。まあとにかくすごいコードが書かれていて、私は正しさを検証することは諦めた。
気づけば12月も27日になっていた。練習ラウンド前々日である。
大急ぎで翌日、彼は犬に敵を妨害させる動作を実装した。敵の侍からフィールドを眺め、各埋蔵金に至るまでの最短経路の道中に評価値を等分して置いていく。このようにして出来上がったマップでは、あるマスに置いてある値が大きければ大きいほど、そのマスは敵にとって価値があるマスだということになる。大きな埋蔵金に近づくためにはそのマスを通る必要があるからだ。だから犬はそんなマスへ移動して居座り、敵の侍の自由を奪う。妥当だとは思うが、ただ一つ問題があった。最短経路を一通りしか見ていないのである。この格子状のマップで。最短経路などいくらでもあるにも関わらず。ただ、我々はわかっていてその問題を無視した。練習ラウンド前に少し犬がマシな動きをするようになれば良いと思っていた。まあね、確かに時間もなかったし、一時的なことならば最善かもしれない。しかし、驚くべきことにというか、この犬の動きは決勝イベント前日まで変更されることはなかった。もはや犬が不憫に思える。ほんとになんで?
迎えた第1回練習ラウンドは、まだ参加人数が少なかったこともあってとりあえず全勝している。そこから考えると取り掛かり始めは相当早かったと思われる。
第2回練習ラウンド (1/13 JST) まで
さて、練習ラウンドを終えてから正月までは何もしなかった。次の行動は1月2日から始まっている。私が作業できるようになった代わりに montplusa くんが作業できなくなり、しばらくは私だけで作業する日々が続いた。
まず私は第1回練習ラウンドに提出された monta_evaluate を見て、ソースコードが私の手に終えるレベルではないことを知った。新年初の作業はまずこの monta_evaluate の動作をなるべく保ちながら書き直す作業だった。その成果が後に最終提出する AI の基盤となる monk1 である。 monk1 のコードは montplusa くんにはとても評判が悪かったが、押し切った。
この頃には「もっと手軽に戦略の成果を試したい」という声があり、また montplusa くんがしばらく作業できないというタイミングもちょうどよかったので、 monk1 を書きながらテストツールを作る作業も始めた。現在の AI と指定した敵とをまとめてすべての preliminary-candidates なマップの上で試して結果の集計をするプログラムである。ついでにそれを Pull Request と同時に実行する GitHub Actions も追加した。結局テストは手元で実行するほうが圧倒的に早かったのであまり役には立っていないが、逆に少し遅い CPU でタイムアウトしないかの参考程度の意味はあった。
テストツールが使えるようになると、想像以上にゲームマネージャーとビジュアライザの間に齟齬があったことに驚いた。それにはゲームマネージャーが正しいことも、ビジュアライザが正しいことも、どちらも間違っていることもあった。それらについては発見次第適宜大本の GitHub リポジトリ で報告させてもらったが、どれも素早く対応してもらえたことは助かった。ただ、テスト結果の信憑性が低い時期にはそれに依拠して AI を改善するのも若干不安があり、しばらくの間は開発を見送りつつバグを叩こうという話も起こっていた。このあたりで少し気持ちが離れてしまった部分はあったと思う。しばらくは monk1 に触れず、他の予定を消化したり CodinGame に明け暮れたりする日々が続いた。そう、 CodinGame の Bot Programming と SamurAI Coding はゲーム性も近く、しかし CodinGame はゲームが複数用意されていて面白そうなものを選ぶことができるとか、いつでも全世界の人に挑戦できて即座にフィードバックが返ってくるとか、そういう点で優れていた。
第2回練習ラウンドの期限が迫ってきて、流石に何かしらしなければならないだろうと言いながら、簡単に実装できる軽い修正を行った。
- 一度トライして妨害された埋蔵金はしばらくの間無視する。おそらくその埋蔵金は犬が守っているから取れないだろう。
- 味方の犬の下にある埋蔵金は無視しないようにする。通常エージェントの下にある埋蔵金は掘ることもできないが、味方の犬だけは避けてもらえば取ることができる。
- invalid move などで結果的に REST として扱われた REST は斜め移動可能として扱わない。そのような結果的な REST は斜め移動のためのエネルギーを充填しないことに気づいた。
- 同じ行動を繰り返さない。決定的アルゴリズムである以上、一度 stuck してしまえば一生 stuck する。それを避けるためには同じ行動を繰り返さない必要があり、一定期間同じマスで同じ方向に対して行動を取ることを禁じた。
ざっとそんな程度の本当に軽い修正だけ施して、第2回練習ラウンドに提出した。参加者も少しずつ増えていたが、まだ先にはじめた分だけリードがあり、このときもとりあえず全勝した。
予選 (2/2 JST) まで
当初の締め切りは1/26 JST だったが、一度マネージャーに大きなバグ修正があったためか、その後予選提出期限は一週間程度延長された。
第2回練習ラウンドの前後から、私は Python に限界を感じていた。と言うと Python に失礼なので正確に言い直そう。私は自分の能力で Python の性能を引き出すことに限界を感じていた。実のところやってみたいことはたくさんあった。例えば一手全探索もそうだ。でも Python での我々の AI の思考時間は限界で、全探索どころかもう一回 BFS を走らせるとタイムアウトしてしまうだろうという状況だった。
色々と考えた。明らかにグラフアルゴリズムが重たいから、そこだけ切り取って C++ で実装して Python からは呼ぶだけにしてみようか、とか。しかしそれは明らかにコンパイル作業の複雑さを増すし、バージョン違いでサーバーでだけ動かなかったりしかねない。それならばと思い、第2回練習ラウンドを終えた直後、私は monk1 をまるごとすべて C++ で書き直し始めた。そうすればそのまま書き直しただけでも実行時間は 1/10 ~ 1/20 程度にはなるだろう。しかし結局それは半分ほど書き直したところで montplusa くんに止められた。「やってもいいが、 C++ にされたら私はもう分からなくなるし書かない」と。
それを諦めたとて、元の monk1 を改善したわけでもなかった。なにもないのはということで、montplusa くんが休憩した次のターンにおいては最初の一手の斜め移動はターン数が1短縮されるという当たり前のことを正しく実装して PR を出した。それが 1/20 のことだった。私は彼にいくつか細かい点で修正を依頼したが彼には修正する時間がなく、結局締切直前 2/1 になって私が修正してマージした。それをそのまま提出した。
それでも予選は2位で通過した。しかも1位はあれだけ参考にした ValGrowth さんだったので、もうこれは仕方ないかあ、といった空気に支配されていた。
決勝イベント締め切り (3/9 JST) まで
このままでは勝てないことは分かっていた。そもそも予選 2 ~ 4 位の間に勝利数の差はない。得点差でわずかに競り勝っただけだ。間違いなく彼らはまた強化して参加するだろう。5 位以下だって全く油断ならない。しかしもうどう改善すべきかということもわからなくなっていた。これ以上の「直せたら良いこと」「できたらいいこと」には計算時間が必要だったが、もうほとんど捻出できない。思いつかないので気分転換に CodinGame をやって沼にはまった。
そもそも何が強いのかもわからなくなってきた。テスターで自分同士を戦わせると 0 対 0 で引き分ける。そして評価パラメータを一つ変えると、前の AI 対変更した AI が 45 対 55 、のように結果が出る。ではこの変更をした AI の方が元のより強いのかというと、この AI 、残りの 45 試合では負けているのである。決勝イベントはリーグ戦でも平均的勝率でもなく、選ばれた 1 つのマップですべてが決する。行った変更が 0 対 0 の状態から 0 対 10 になる、つまりただ勝ち試合だけが増えるだけという自明な改善はそうそうない。 8 割の勝率が出たとしても、残りの 2 割のマップが決勝戦で選ばれてしまうなら前の AI の方を提出しておく方が良かった。
ともかく、この期間中はどういう AI を出すのが良いのだろうねという話をずっとしていた記憶がある。最終的には我々はいくつかの改善をして、予選の AI に対して勝率 85% 、総合得点で 1.5 倍をとれる AI を提出した。でもこの AI は 15% のマップでは前の AI に負ける。マップによっては第1回の練習ラウンドに出した monta_evaluate にすら負ける。引き分けはほとんどない。これで出しても良いのか?
ちなみに、総合得点が 1.5 倍になったからくりは不遇だった犬にある。ラストスパートで犬の妨害に関する件の雑な方式をまるまる書き直し、より妥当な方式になった。その書き換えについては話には聞いているけれど説明できるほどではない。とりあえず妥当な方式になった。その結果旧 monk1 は思うように得点が取れなくなって、つまり相手を押し下げることで 1.5 倍になったということだ。
我々は結局この改善したように見える AI を提出するかどうか最後まで迷った。どこかのマップでは勝てるようになったが別のマップでは負けるようになる、それは単に AI が特定の特徴に特化しているだけで、偏りを大きくしているだけで、別に改善ではないのでは?
テスターは、我々が障害がなにもない取り放題ステージ (敵の犬が隔離されている、犬にとって歩きづらい etc.) に弱いことを明確に示していた。それは有り体に言えば我々の侍がビビリだということである。強化された侍の移動は犬が侍を完全に押さえつけることをよしとせず、逆に言えば侍は犬をかいくぐることができた。だから monk1 は犬と向かい合うと犬を避けるために犬を翻弄しようとするのだ。犬が粘着質なら効果があるだろうけど、そうでないなら時間の無駄でしかない。敵の犬が粘着質でも、自分の犬が同じくらい相手に粘着できていなければやっぱり負けてしまう。
でもまあ結局どうしようもないので出した。平均的には予選の monk1 よりは強い。
決勝イベントでは、我々の気持ちとしては残念ながら準々決勝で敗退することになった。問題となったマップは市松模様に 4x4 の穴と 4x4 の平地が重なっているマップだった。コマ落ちもあってしっかり見られなかったが、このようなマップは、犬がなまじ「移動できてしまう」にも関わらず基本的に遠回りを選ばされるマップであり、侍に追いつくことが難しい。ところが我々は犬に妨害されることを恐れ強気な行動はしない。特に REST を多用する。結果的に、何も考えず動いていれば振り切れたかもしれない犬を、しかし振り切れずにずっとじゃれ合い続けていたようだった。
我々のやり方についてと思うこと
色々と反省はある。少なくとも、モチベーションは失いすぎである。
少なくとも色の違う複数の AI を作ってみて、テスターの候補に追加しておくべきだった。
monk1 を進化させていった過程の各世代はテスターに含んでいたが、それはあくまでもある一本の系譜でしかない。別の系譜を持つ、例えば全探索する AI をいくつか追加しておけばよかった。
C++ に書き換えていた AI をとりあえず完成させておくべきだった。
実際には使わなかったとしてもそれを一つのテスターに加えることだってできたし、純粋に速度的アドバンテージを取れるのはその後の発展のためにも良かったと思う。 montplusa くんがかけないなら私が書けばよかった話でもある。
テスターが出力する統計的結果に頼りすぎた。
これについては仕方のない部分もある。テスターは 2000 試合以上を 30 分程度で終わらせてしまうが、我々が確認するのはそれほど短い時間では済まないので、敗北した試合が 10 件もあれば見るのは億劫になる。だが、それぞれの試合を一つずつ見れば不適当な動きは散見されたと思う。特に決勝前については、決勝戦がマップ一つで決まるということをもう少し意識するべきだった。
よかったこと
特に後半の動きが悪かったことは事実なので後半につれて書き様は重たくなってしまったが、別に今の気分がそれほど重たいわけではない。そもそも良かったことだって山ほどある。
まず Bot Programming の楽しみを思い出した。自分のプログラミングの原点はコンピュータを自分の意のままに動かすことだった。そして自分がやる仕事をコンピュータが高速に終わらせる様を見るのが好きだった。
CodinGame の Compete モードを知った。今まで CodinGame は Practice しかやったことがなかった。ビジュアライザがきれいだなと思う反面、敵もいないので、やっていることは普通の競プロと同じである。しかし Compete モードなら敵がいる。自分が書いた Bot が賢い動きをして敵を倒すというのは、自分の原点を思えばそれはもう楽しい体験だ。
久しぶりに複数人で楽しみながらプログラミングをした。基本的には普段は一人でプログラミングをすることが多いし、大規模なプログラムとなると個別の作業が組み込まれていくという印象が強くなる。今回のように一つの目標があって方針を相談しながら挑戦することは、それらとは違う楽しみがある。特に頭のいい人と組んで何か目的を達成するのは楽しい。
いろいろとある、本当に色々とある。
おわりに
冒頭にも書いたことだが、これだけ長い時間をかけてトライした大会は初めてだ。色々なことがあったし、それについてはもう十分話した。
大変良い体験をした。この大会に関わられたすべての方々に改めて感謝をして、この文章を閉じようと思う。
この日記をここまで読む人もいないとは思うが、もしそんな方がいたら、こんな長い独り言にお付き合いくださってありがとうございます。
FnBox
Rust Book 勉強会 #4 で発表をしてきた。ジェネリクスとトレイトについての章を担当したが、まあ、かなり重かった。本当はライフタイムの節までやる予定だったが、完全に時間がなかった。私は別に何時間でも話していられるのだが、私自身が何週間もかけて理解したことを2時間ほどで凝縮したわけなので、参加者の皆さんへの負担はかなり高かったと思う。昔は所有権とライフタイム、ジェネリクスとトレイトで分かれていたと思うのだが、この 3 本立てはかなり辛い。
さて、それはともかくとして、最後の方で FnOnce の話が登場した。 FnOnce は関数呼出演算子を提供する3つのトレイト Fn, FnMut, FnOnce の一つである。名前から分かるように、 FnOnce は一度だけしか呼び出せない関数を表している。この手の関数の例としては、クロージャであって、キャプチャした変数の所有権を利用するようなものが考えられる:
let s = "hello".to_string(); let c = || { drop(s); };
このクロージャは s を環境内にキャプチャしている。 drop() は所有権を要求するので、s の実体がないとならない。よって c が定義された段階で、 s を環境内にムーブする。このクロージャを実行するためには s の実体が必要なので、初回の呼出で環境内のs が所有権ごと処理本体にムーブされてくる。結果として、このクロージャは二度呼ぶことができない。
まあ、詳しいことは以前散々書いたので読んでいただけるといい。
ところで、クロージャのように匿名でユニークな型をもつものは、以前は、関数から直接返す方法がなかった。 Rust では型推論を関数内に敢えて限っており、関数の引数や戻り値は必ず明示的に型を書かなければならない。よって型名を表記できないものは返すことができない。
今日では非常に有り難いことに impl Trait によりこのクロージャが直接返せるようになっている。 impl Trait はイテレータを返すのに非常に便利だし、クロージャを返すのに必要な、本当に素晴らしい機能である。今のところ、ある単一のクロージャを返したいときは impl Trait を使うのが一番よい:
fn get_closure() -> impl Fn() -> String { || "hello".to_string() } let c = get_closure(); println!("{}", c()); // => hello, world
では、以前は関数でクロージャを返したい時はどうしていたか。トレイトオブジェクトというものを使っていた:
fn get_closure() -> Box<dyn Fn() -> String> { Box::new(|| "hello".to_string()) } let c = get_closure(); println!("{}", c());
トレイトオブジェクトをざっくり説明すると そのトレイトを実装した型 という型であって、型名は dyn Trait となる。ただし具体的な型が何なのかによってそのサイズは任意になり得るので Sized ではなく、必ず 参照 &dyn Trait または Box<dyn Trait> の形で扱うことになる。この参照は あるオブジェクト自身へのポインタ と 仮想関数テーブルへのポインタ をもつ。つまり、オブジェクト指向言語における 派生クラスのポインタを基底クラスのポインタとして見る ようなことである。
トレイトオブジェクトを使う必要性やメリットとしては次のようなことがある。
- 具体的な型名が判明していなくても書ける。
- そのトレイトを実装していさえすれば、実際の型は異なっていても同じ型として扱える。
しかし、その目的故に次のようなデメリットも目立つ。
- メソッド呼び出しなどを必ず動的に解決することになる。
- 関数から返す場合は、必ず実体をスタックではなくヒープに確保しなければならないのでそのコストがかかる。
- 参照の形でしか扱えないため、
&selfか&mut selfを引数に取らない関数は呼び出せない。
特に 3 つ目の制約は大きい。反するのは関連関数 (static 関数) と、 self を取る関数である。関連関数の方は、そもそも Type::function() の形でしか呼び出せないので、具体的な型が分かっていない間は呼び出しようがない。また、 Sized でないものは関数の引数に渡せないので、 self をとる関数も実行できない。
さて、 FnOnce は一度しか実行できないクロージャが実装しているが、それは何故だったか。 FnOnce になるようなクロージャは環境を関数本体へムーブする必要があるからであった。つまり FnOnce の関数呼出演算子を実装するメソッドは self をとっているはずだ。実際、今のところの FnOnce トレイトは次のようになっている(変更される可能性がある):
pub trait FnOnce<Args> { type Output; fn call_once(self, args: Args) -> Self::Output; }
したがって、 FnOnce のトレイトオブジェクトは呼び出すことができない:
fn get_closure() -> Box<dyn FnOnce() -> String> { let s = "hello".to_string(); Box::new(|| s) } let c = get_closure(); // c(); // 型のサイズが静的に決定できないため、ムーブできずにエラー。
これができるようになる機能は現在 unsized_locals として実装されているところである。実は nightly であれば unsized_locals を有効化すると既に実行することができる。ではこれが安定化するまでは、どのようにすれば Box<dyn FnOnce> を呼び出すことができるのか?
その前に、メソッドがとりうる self 型の種類を復習しておこう。というか、それを見ると解決策は一瞬で見えるはずだ:
impl Foo { fn by_value(self: Self) {} // fn by_value(self) {} fn by_ref(self: &Self) {} // fn by_ref(&self) {} fn by_mut(self: &mut Self) {} // fn by_mut(&mut self) {} fn by_box(self: Box<Self>) {} // (省略形なし) }
上三つは馴染みがあるだろうが、実はなんとメソッドは Box<Self> を取ることもできる:
struct X(i32); impl X { fn by_box(self: Box<Self>) { println!("{}", self.0); } } let bx = Box::new(X(3)); bx.by_box(); // => 3
(ちなみに arbitrary_self_types が有効化されると *const Self や Rc<Self> など、様々な型が self になれるようになる。)
...ということは、 Fn 系トレイトに Box<Self> をとるものがあれば解決するのではないだろうか?
ある。ただし安定化はされていないので #![feature(fnbox)] が必要になる。トレイト FnBox である:
pub trait FnBox<A> { type Output; fn call_box(self: Box<Self>, args: A) -> Self::Output; }
このトレイトは、 F: FnOnce<A> を満たす全ての型 F に対して実装されている:
impl<A, F> FnBox<A> for F where F: FnOnce<A> { /* snip */ }
ということで、何のことはなく、 FnOnce ではなく FnBox を使ってやればよかったのだ:
#![feature(fnbox)] use std::boxed::FnBox; fn get_closure() -> Box<dyn FnBox() -> String> { let s = "hello".to_string(); Box::new(|| s) } fn main() { let c = get_closure(); println!("{}", c()); // 問題なく呼び出せる。 // c(); // 二回目以降はもちろんエラー。 }
ただし、 FnBox はおそらく安定化されない。理由はこれは Box<dyn FnOnce> が直接実行できない間の代替であって、 unsized_locals が安定化されれば不要になるからである。
Arch Linux に Quartus / ModelSim をインストールする
ひょんなことから FPGA を扱う機会に恵まれた. FPGA では Intel の Quartus なるソフトウェアを使って開発を行うらしい. なにはともあれインストールをしなければならない. ところがこのインストールがなかなか曲者だった. 嵌りまくったのでここにメモを残しておく.
なお, これはとりあえず動いた後に適当に思い出しながら書いているので, 正確でなかったり, 抜けていたり, 必要でない手順が含まれていたりする可能性が大いにある.
Quartus
まずは開発ツールである Quartus をインストールする. いくつか嵌りどころはあるが, 大した問題ではない. いや, 普通に考えるとそれなりに深めの嵌り所なのだが, この後に出てくる問題に比べると全く大したことではない.
まずは Intel のダウンロードページからソフトをダウンロードする. ダウンロード場所がなかなか見つからなくて迷った. これを書きながら今探しても見つけられない. 過去の私はどこからダウンロードしてきたのだろう...
ちなみにダウンロードサイトには ModelSim のインストーラもダウンロードできるが, Quartus のインストーラに全く同じものが同梱されているので必要なさそうだ.
現時点では Quartus-lite-18.0.0.614-linux.tar が最新である。これを適当にディレクトリ quartus にでも展開すると, 次のような構成が表れる.
. ├── components │ ├── ModelSimSetup-18.0.0.614-linux.run │ ├── QuartusHelpSetup-18.0.0.614-linux.run │ ├── QuartusLiteSetup-18.0.0.614-linux.run │ ├── arria_lite-18.0.0.614.qdz │ ├── cyclone-18.0.0.614.qdz │ ├── cyclone10lp-18.0.0.614.qdz │ ├── cyclonev-18.0.0.614.qdz │ ├── max-18.0.0.614.qdz │ └── max10-18.0.0.614.qdz ├── readme.txt └── setup.sh 1 directory, 11 files
さて, これのインストールだが, ZEROからのFPGA : Altera(Intel)のFPGA開発ツール「Quartus Prime」をUbuntuにインストールする を大いに参考にさせていただいた. スクリーンショット付きで分かりやすく解説されているので, ここを読めば問題なくインストールできるだろう. 参考サイトにも書かれているが, 注意点としては,
- 最初のコンポーネント選択では ModelSim と Quartus Help を外しておく.
- インストールが完了してもなぜかターミナルの制御が戻ってこないので, 完了したら Ctrl + C でプロセスを終了させる必要がある.
ちなみにインストールするディレクトリはお好みだが, ここではとりあえず /opt/intelFPGA_lite/18.0 へインストールすることにする. インストールが完了すると, /opt/intelFPGA_lite/18.0/quartus/bin/quartus を叩くことで Quartus が起動できるはずだ.
ModelSim
先の参考サイトには ModelSim のインストールが含まれていない. components/ModelSimSetup-... がインストーラなので, ModelSim のインストーラを実行してインストールしておく. インストールディレクトリを Quartus をインストールしたディレクトリ (ここでは /opt/intelFPGA_lite/18.0) に揃えておくとよいだろう. まあそれは必須ではない.
さて, ModelSim を実行するコマンドは vsim である. インストール先を /opt/intelFPGA_lite/18.0 にしたならば, このコマンドは /opt/intelFPGA_lite/18.0/modelsim_ase/bin 以下にある. ではさっそく実行してみよう.
% /opt/intelFPGA_lite/18.0/modelsim_ase/bin/vsim Error: cannot find "/opt/intelFPGA_lite/18.0/modelsim_ase/bin/../linux_rh60/vsim"
なるほどまずはエラーから. とりあえずターミナルで様子を探ってみる.
% cd /opt/intelFPGA_lite/18.0/modelsim_ase/bin % ls -l 合計 4 drwxr-xr-x 3 ... ... 4096 8月 25 02:48 NONE lrwxrwxrwx 1 ... ... 6 8月 25 01:18 drill -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 dumplog64 -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 hm_entity -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 jobspy -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 mc2_util -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 mc2com -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 mc2perfanalyze -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhcvt -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhdel -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhdir -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhgencomp -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhlib -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhmake -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhmap -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qhsim -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qverilog -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qvhcom -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 qvlcom -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 sccom -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 scgenmod -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 sdfcom -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 sm_entity -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 triage -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vcd2wlf -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vcom -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vcover -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vdbg -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vdel -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vdir -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vencrypt -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 verror -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vgencomp -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vhencrypt -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vlib -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vlog -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vmake -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vmap -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vopt -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vovl -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vrun -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 vsim -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 wlf2log -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 wlf2vcd -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 wlfman -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 wlfrecover -> ../vco lrwxrwxrwx 1 ... ... 6 8月 25 01:18 xml2ucdb -> ../vco
なんと, すべて ../vco とやらへのシンボリックリンクである. vco は, 実行されたときの自分自身の名前を見て動作を変えるタイプのファイルである. こういう動作は busybox や extractbb (本物は dvipdfmx) でも見られ, 面白い. それはともかくとして, ../vco は実はシェルスクリプトなのでエディタで開ける. すると, 204-210 行目にこういうコードがあるはずだ.
case $utype in 2.4.[7-9]*) vco="linux" ;; 2.4.[1-9][0-9]*) vco="linux" ;; 2.[5-9]*) vco="linux" ;; 2.[1-9][0-9]*) vco="linux" ;; 3.[0-9]*) vco="linux" ;; *) vco="linux_rh60" ;;
これは Linux カーネルのバージョンにより何か分岐しているコードのようなのだが, 問題は Linux 4.x 系の分岐が含まれていないこと. 現時点でうちの Arch Linux は 4.18.4 なのでここで分岐に失敗している. linux_rh60 というのはエラーメッセージにも含まれていたし, 怪しい.
ということで, 3.[0-9]*) の後ろに一行追加する.
case $utype in 2.4.[7-9]*) vco="linux" ;; 2.4.[1-9][0-9]*) vco="linux" ;; 2.[5-9]*) vco="linux" ;; 2.[1-9][0-9]*) vco="linux" ;; 3.[0-9]*) vco="linux" ;; 4.[0-9]*) vco="linux" ;; *) vco="linux_rh60" ;;
編集したらファイルを保存する. このファイル, なぜか書き込み権限がないので注意. Vim で開いたら読み込み専用になった. 別に所有者は自分自身なのでなんとでもなるが.
これで動け, と思うのだが...
% ./vsim /opt/intelFPGA_lite/18.0/modelsim_ase/bin/../linux/vish: error while loading shared libraries: libXft.so.2: cannot open shared object file: No such file or directory
なるほどね. ちなみにこのメッセージは一旦できた環境から一部をわざと壊して再現しているので, エラーメッセージ内のライブラリ名などは違うかもしれない.
で, 新しく vish という人物が登場してきた. どうもさっきのファイル vco は vish を呼び出すらしい. エラーメッセージは見慣れた依存関係エラーであるから, vish に足りていないライブラリをまずは探す.
% cd ../linux
% ldd vish
linux-gate.so.1 (0xf7f3e000)
libpthread.so.0 => /usr/lib32/libpthread.so.0 (0xf7ef6000)
libdl.so.2 => /usr/lib32/libdl.so.2 (0xf7ef0000)
libm.so.6 => /usr/lib32/libm.so.6 (0xf7e23000)
libX11.so.6 => /usr/lib32/libX11.so.6 (0xf7cd6000)
libXext.so.6 => /usr/lib32/libXext.so.6 (0xf7cc1000)
libXft.so.2 => not found
libXrender.so.1 => /usr/lib32/libXrender.so.1 (0xf7cb5000)
libfontconfig.so.1 => not found
librt.so.1 => /usr/lib32/librt.so.1 (0xf7caa000)
libncurses.so.5 => /usr/lib32/libncurses.so.5 (0xf7c47000)
libc.so.6 => /usr/lib32/libc.so.6 (0xf7a6a000)
/lib/ld-linux.so.2 => /usr/lib/ld-linux.so.2 (0xf7f40000)
libxcb.so.1 => /usr/lib32/libxcb.so.1 (0xf7a3e000)
libXau.so.6 => /usr/lib32/libXau.so.6 (0xf7a39000)
libXdmcp.so.6 => /usr/lib32/libXdmcp.so.6 (0xf7a32000)
これは後で再現しているだけなので, 実際はもう少しいろいろ足りないライブラリがあった. not found となるライブラリがなくなるように, 全てのライブラリをインストールする必要がある. ここで私は「あれ? freetype が入ってないわけなくない?」と思ったのだが, 騙されるなかれ, じつはこの vish は 32-Bit バイナリなのである.
% file vish vish: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 2.6.4, BuildID[sha1]=77d8354d389082fe6128a20bc3f4db5ded41a81b, stripped
あーはいはい. つまり必要なのは lib32-* 系のライブラリである. 必要なパッケージの名前はほとんどライブラリの名前と同じなので, 探すのはそう難しくない. pacman -Ss を使って検索し, pacman -S を使ってガンガン入れていく. なお, lib32-* 系のライブラリはレポジトリ [multilib] に入っているのだが, このレポジトリはデフォルトで無効になっている. 有効にしていない人は /etc/pacman.conf の [multilib] の部分をアンコメントして有効にする必要がある.
さあ, 全ての依存を解決したぞ. これでいけるだろう.
% ../bin/vsim
Error in startup script:
Initialization problem, exiting.
Initialization problem, exiting.
Initialization problem, exiting.
while executing
"Transcript::action_log "PROPREAD \"$key\" \"$value\"""
(procedure "VsimProperties::Init" line 59)
invoked from within
"VsimProperties::Init $MTIKeypath"
(procedure "PropertiesInit" line 18)
invoked from within
"PropertiesInit"
invoked from within
"ncFyP12 -+"
(file "/mtitcl/vsim/vsim" line 1)
** Fatal: Read failure in vlm process (0,0)
うーん.
前半部分のエラー内容は異なるかもしれない (というか事実違った気がする) が, とりあえず大切なのは一番最後の Fatal: Read failure in vlm process (0,0) である. さっぱり分からないのでググると割と簡単に情報が得られる. それによると libfreetype2 のバージョンが高いとエラーを起こすらしい. 起こさないようにするにはだいたい libfreetype2 2.4.7 くらいをもってこればよいそうな. ちなみに今の Arch Linux には freetype 2.9.1 が入っている. 高い.
まあそうだよね. Linux カーネルの分岐に 3.x までしか含まれていないくらい古い時点で, 何かしら依存ライブラリでこけると思っていた. freetype 2.4.7 なんて古すぎて AUR にもないのでソースからコンパイルする必要がある.
まず必要なのは freetype-2.4.7.tar.gz . また, 最新の fontconfig はこんな古い freetype とは仕事できないので, 当時の fontconfig を持ってくる必要がある. どれくらいの fontconfig が必要なのか分からないが, とりあえず fontconfig 2.5.0 を選んだ (根拠はそれほどない) . これもソースからコンパイルする必要があり, fontconfig-2.5.0.tar.gz が必要になる.
まずは適当に検索して freetype-2.4.7.tar.gz を入手する. これを展開して由緒正しい ./configure && make && sudo make install の流れをすればよいのだが, ここでは 32-Bit のバイナリを生成する必要があることに注意する. autotools - Build 32bit on 64 bit Linux using an automake configure script? - Stack Overflow によれば, それには configure に対して --build=i686-pc-linux-gnu "CFLAGS=-m32" "CXXFLAGS=-m32" "LDFLAGS=-m32" なるオプションをつければよいらしい.
こんな古い freetype の, しかも 32-Bit 版を /usr/local 以下にインストールするのは気が引けるが, そうしないと次の fontconfig のビルドが失敗する. 全てが終われば削除しても問題なさそうなので, 一時的にでも sudo make install しておく.
続いて fontconfig をビルドする. これのビルドは freetype と同様なので省略する. アーカイブを展開して, 例のオプションをつけて ./configure し, make && sudo make install すればよい.
ふー疲れた. そうして, ようやく vsim が起動できるようになったはずだ. 一度試してみるとよい.
おまけ
これでいい人はこれでよいのだが, このままでは /usr/local 以下にこの古い 32-Bit なバイナリ達が残ることになる. 特に, /usr/local/bin は /usr/bin より優先度が高いので fc-* 系のコマンドが /usr/local/bin にある古いものになってしまう. これは嬉しくないので, なんとかここから移動したい.
ModelSim が欲しいのは libfontconfig.so.1 と libfreetype.so.6 の二つ. これらを別の場所へコピーして退避する.
退避先だが, ModelSim のインストール先ディレクトリに lib32 という名前のディレクトリを作った. この lib32 ディレクトリに /usr/local/lib から libfontconfig.so.1 と libfreetype.so.6 をコピーしてくる (私は不安だったので libfontconfig.so* と libfreetype.so* を, cp -R コマンドで SymLink ごとコピーしてきた). コピーしてしまえば元のあいつらはもうアンインストールしてしまう. freetype をビルドしたディレクトリに入り, sudo make uninstall すると freetype がアンインストールされる. 同様に fontconfig をビルドしたディレクトリに入り sudo make uninstall すると fontconfig がアンインストールされる.
lib32 がライブラリ検索パスに含まれていないため, このままではまた ModelSim がエラーを出す. 先の lib32 ディレクトリを LD_LIBRARY_PATH に追加することで使えるようになる. おあつらえ向きに vco などという全コマンドが経由するシェルスクリプトがあるので, こいつを編集して達成しよう.
vco の末尾には次のような, 見るからにコマンドを実行してそうな行がある.
if [ -z "$*" ] ; then exec "$arg0" else exec "$arg0" "$@" fi
ここを次のように書き換えてしまえばよい.
if [ -z "$*" ] ; then exec env LD_LIBRARY_PATH="$LD_LIBRARY_PATH:$dir/lib32" "$arg0" else exec env LD_LIBRARY_PATH="$LD_LIBRARY_PATH:$dir/lib32" "$arg0" "$@" fi
これで, システムをクリーンに保ったまま vsim が起動できるようになる. 弊害として vsim 起動時に Fontconfig error: Cannot load default config file なるエラーが出るが, まあいいだろう. vsim コマンドを打ってしばらく待つと, 古めかしい出でたちのウィンドウが現れる. めでたい. あーーー, 疲れた.
おわりに
起動できることは確認したが, それ以上の動作確認はしていない. またどこかでエラーが出るかもしれない. 怪しいとしたら freetype/fontconfig だろうが, こいつらは所詮フォントをレンダリングするだけなのでそれほど致命的なエラーは起こさないと信じる. とは言うものの, 今はまさにそのフォントレンダラがなぜか致命的な原因だったわけだが...
この手の問題はやって解決できないことはほとんどないが, かなり疲れる.
競技プログラミングのための自分用アシスタントツールを作った。
最近, 弱小ながら競技プログラミングをやっている. 競技プログラミングは, 与えられた問題を解くプログラムを書いて提出する競技だ. 正しいプログラムを早く提出できるほど高得点を得られる.
競技プログラミングをするときには, 書いたプログラムが正しいかどうかをまずは問題文に書かれているサンプルケースで検証する. つまり, フォーカスをエディタに切り替えて, プログラムを書き, 端末にフォーカスを移してコンパイルし, 実行し, ブラウザにフォーカスを移し, サンプルの入力部分を正しく選択し, コピーし, 端末にフォーカスを移して貼り付けし, 出力を目視し, ブラウザにフォーカスを移し, サンプルの出力と一致するかを確かめる. 面倒くさい. それも, 確認が一回で済むような強者ならまだしも, たいていはサンプルとすら一致しない. するとバグを見つけて修正し, コンパイルし直しから全く同じプロセスを経て確かめなければならない.
入力をファイルに保存してしまって, 以降はリダイレクトで済ませる手がある. これをするとコピペの手間が省ける. しかしそれでもファイルを作ったりいろいろ面倒だし, 出力は目視だし, 実行は逐一コマンドを入力しなければならない.
というわけで, 自分のためにアシスタントツールを作成した. その名も procon-assistant . いくつかの機能がある.
% procon-assistant
Procon Assistant
Usage: procon-assistant [command] [options]
List of commands:
initdirs [name] [num] initializes directories tree (name/{a,...,a+num})
init initializes files in directory
fetch [ID] downloads test cases from webpages
[ID] is:
- aoj:xxxx id xxxx of Aizu Online Judge
addcase adds new sample case. creates inX.txt, outX.txt in current directory.
run runs and tests current solution (main.cpp) with input inX.txt.
initdirs / id
コンテストのためのディレクトリ構造を作成する.
コンテストは, 大抵はいくつかの問題から成る. たとえば 6 問など. 各問題に対してディレクトリを作るわけだが, けっこう面倒だ. というわけで, ディレクトリ構造を作成してくれる機能を付けた.
コンテスト名のディレクトリの下に, [num] で指定した数の空ディレクトリ a, b, c, ... を作成する. なお文字の種類を変更 (数字にするなど) はできない. 面倒だし自分にはあまり必要ないので.
init / i
コンテストのためのファイルを作成する.
カレントディレクトリに #include <...> や using namespace std; など必ず使う要素を入れたファイル main.cpp を作成し, これをエディタで開く. エディタで開くには open という名前のコマンドが必要で, こういう名前のコマンドにファイル名を渡すようになっている. open はたとえばエディタへの symlink であるとか, 何らかのシェルスクリプトとかで準備してパスの通ったディレクトリに置く.
ほとんど何も入ってない. テンプレートを指定する機能はない. 面倒だし自分には十分なので.
fetch / f
コンテストからテストケースをダウンロードする.
カレントディレクトリに, コンテストのテストケースをダウンロードする. 一つずつ in1.txt, out1.txt, in2.txt, out2.txt, ... というように作っていく. 現状 AOJ と AtCoder に対応. ただ, やっつけ仕事なのと今日実装したので使い勝手は不明. そもそも AtCoder のコンテストってリアルタイムにログイン無しで問題見えたっけか. 普段参加登録してから開くのでそれすら知らない.
addcase / a / ac
手動でテストケースを追加する.
カレントディレクトリに inX.txt, outX.txt を作成して, エディタで開く. X にはカレントディレクトリに同名のファイルが存在しないような最小の整数が入る. 手動で追加するときに便利か? fetch を実装するまではここでコピペしてた. fetch できないコンテストでも使えそう.
run / r
プログラムをコンパイルし, 各テストケースを実行する. いい感じにテスト結果を表示する. ここでは示せないが, 実はちょっと色もついている. 色付き出力には自作の colored_print クレートを使用した (言い忘れていたが, Rust で書いた) . "Your solution was Sample Case Passed." って変な英語だが, まあそれは英語力がないからなので仕方ない (他の色々な部分も残念ながら「英語っぽい何か」にしかならなかった) .
% procon-assistant run
Compiling main.cpp
Running 4 testcases (current timeout is 1000 millisecs)
Finished running
PS in1.txt
PS in2.txt
PS in3.txt
PS in4.txt
Your solution was Sample Case Passed.
コンパイルオプションはハードコーディングされている. 必要なら変えて再コンパイルすればよいと思って. Time Limit Exceeded も 1000ms 固定になっている. まあ TLE はそれを判定するというより, うっかり無限ループとかになっているやつも最大 1000ms で終了させるためにある.
判定はガバガバなので, たとえば改行コードが CRLF になってたりすると Linux 環境では Presentation Error になったりする. 当然一致判定をしているだけなので, 複数の解答が有り得る場合などでサンプルとは違う (正しい) 出力をしても Wrong Answer になる.
stdout は完全にキャプチャしてしまうのでデバッグ出力には向かない (Wrong Answer になったときに出力はされるけど) . 変わりに stderr を使う. ただ, 各テストケースを並列に実行するので (テストケースが 1 つでない限り) デバッグ出力は滅茶苦茶になる. コンパイルされたバイナリは普通にカレントディレクトリにあるので, 個別に実行するには普通にテストケースをリダイレクトして直接実行すればよい.
ただのアシスタントなので, 細かいところはやっぱり手動で実行して試すことになるが, 大分手間は減ると思われる. これを使って学習効率が上がるとよいのだが...
Rust のクロージャの環境, Fn* トレイト
クロージャ
クロージャは環境をもつ無名の関数である. 環境はそのクロージャの実行に必要なデータをまとめたものだ. C++ ではラムダ式と言われていて, 関数オブジェクトの糖衣構文である.
Rust のクロージャも C++ と同様に構造体を使って実現される. つまり構造体のメンバとして必要なデータ (=環境) を持ち, その構造体のメソッドとしてクロージャの処理本体を記述する. そう, 別にクロージャは特別な存在ではない.
例えば次のクロージャは,
let x = 3; let closure = || println!("{}", x); closure();
次のように実装できる.
struct ClosureType<'a> { x: &'a i32, } impl<'a> ClosureType<'a> { fn invoke(&self) { println!("{}", self.x); } } let x = 3; let closure = ClosureType { x: &x }; closure.invoke();
...しかし非常に面倒くさい. それでクロージャという形で簡易に使えるようになっているわけだ.
また, ここでは invoke() というメソッドを普通に実行しているが, クロージャは関数呼び出し構文 () で実行できる. 実はこれは C++ 同様 () オペレータのオーバーロードである. Rust では, () のオーバーロードを後半に説明する Fn* 系のトレイトを実装することで行う. unstable なため nightly でしか使えないが, これらのトレイトを使うとクロージャ同様呼び出せるようになる.
#![feature(unboxed_closures, fn_traits)] struct ClosureType<'a> { x: &'a i32, } impl<'a> std::ops::FnOnce<()> for ClosureType<'a> { type Output = (); extern "rust-call" fn call_once(self, _: ()) { println!("{}", self.x); } } impl<'a> std::ops::FnMut<()> for ClosureType<'a> { extern "rust-call" fn call_mut(&mut self, _: ()) { println!("{}", self.x); } } impl<'a> std::ops::Fn<()> for ClosureType<'a> { extern "rust-call" fn call(&self, _: ()) { println!("{}", self.x); } } fn main() { let x = 3; let closure = ClosureType { x: &x }; closure(); }
この通り非常に面倒だが.
クロージャの環境
さて, クロージャは環境を持てる無名な関数だと説明し, 実装例も示した. ところで, ClosureType::x の型が参照 &'a i32 になっていることに気がついただろうか?
それを説明する前に, クロージャの処理が環境を参照するまでに 2 ステップあることを確認しておきたい. これらそれぞれに, 次のように変数の取り方がある.
クロージャを作成したとき, 変数を環境にキャプチャする.
変数を環境内に & 借用する, &mut 借用する, 所有権ごともらいうける.
クロージャを実行するとき, 実行するメソッドに環境を渡す.
本体のメソッドが環境を & 借用する, &mut 借用する, 所有権をもらう.
上記は 2 点とも, クロージャ内部でのその変数の使い方によって自動的に決定する.
外部から環境へのキャプチャ
説明に使う構造体 S は次のように定義する.
struct S; impl S { fn ok_immutable(&self) {} // & 借用で OK fn need_mutable(&mut self) {} // &mut 借用が必要 fn need_ownership(self) {} // 所有権が必要 }
& 借用
特に必要性がない場合, 基本的には & 借用としてキャプチャされる.
let mut s = S; // ^^^ mut は一応 &mut 借用もできるように. 実際は不要 // 操作は & 借用でできる; s は & 借用 let closure = || s.ok_immutable(); { // 次は実際にコンパイルが通るので, // s は & 借用されていると示せる. // もし仮に s がムーブされていた // => ムーブ済み値の & 借用, コンパイルエラー // もし仮に s が &mut 借用されていた // => 複数の借用は存在できない, コンパイルエラー let _y = &s; } closure();
move クロージャを使うことで所有権のムーブ (Copy トレイトを実装していれば Copy) を強制することができる.
&mut 借用
値を変更する必要がある場合, &mut 借用としてキャプチャされる.
let mut s = S; // ^^^ mut は &mut 借用するので必要 // 操作に &mut が必要; s は &mut 借用 let mut closure = || s.need_mutable(); // ^^^ ここの mut は C++ に慣れていると // なぜ必要なのか分からない. // しかし Rust では必要. 詳しくは // 'inherited mutability' を調べるべし. // https://teratail.com/questions/114569 // に分かりやすい回答を頂いた. { // 次のコメントを外すと, 複数の借用は // 存在できない理由でコンパイルエラー // => s は &mut 借用されている // let _y = &s; } closure();
move クロージャを使うことで所有権のムーブ (Copy トレイトを実装していれば Copy) を強制することができる.
ムーブ
所有権を要求する操作をする場合, クロージャは所有権ごとムーブして取り込む. 本来はムーブする必要がないものでも, move クロージャを使うことでムーブ (Copy トレイトを実装していれば Copy) を強制することができる.
let mut s = S; // ^^^ mut は一応 &mut 借用もできるように. 実際は不要 // 操作に所有権が必要; s はムーブされた let closure = || s.need_ownership(); { // 次のコメントを外すと, ムーブされた値が // 使われた理由でコンパイルエラー // => s はムーブされている // let _y = &s; } closure(); // closure(); // エラー, closure はムーブ済み
move クロージャの例.
let mut s = S; // ^^^ mut は一応 &mut 借用もできるように. 実際は不要 // 操作自体は & 借用でできるが s は強制ムーブ let closure = move || s.ok_immutable(); { // 次のコメントを外すと, ムーブされた値が // 使われた理由でコンパイルエラー // => s はムーブされている // let _y = &s; } closure(); // クロージャ自体は Fn なので, 2 回目も問題ない. closure();
クロージャからメソッド本体への環境の借用または移動
次に, キャプチャされた環境からクロージャのメソッド本体に渡されるときについて考える. ここでどのように環境を渡すかということが Fn* トレイトにより分類されている.
なお, クロージャがどの Fn* トレイトを実装するかは処理本体に依存する. これは結局, 上で説明した「外部から環境へキャプチャするときにどうキャプチャされるか」とほとんど同じになる. 唯一違うのは move クロージャを要求するが処理本体では所有権を取得する必要がない場合である. (上の最後の move クロージャの例がまさにそれ. 処理本体では .ok_immutable() 以外は何もしないので. ) 他に例外がないのかと聞かれると自信はまったくない. ...なんか絶対ありそうな気もする.
Fn* トレイト
FnOnce, FnMut, Fn トレイトは, 関数呼び出し構文 func() のオーバーロードに用いられるトレイトであった. クロージャはこれらのトレイトを実装した匿名型の実体ということになる. クロージャが匿名型なのはクロージャによって環境や処理が異なるため, 普遍的なクロージャの型というものが存在しえないからである. (ちなみに同一の内容のクロージャでも型は異なる. )
// 渡された f を arg に適用して, 結果を返す関数 fn apply<F>(f: F, arg: i32) -> i32 where F: FnOnce(i32) -> i32 { f(arg) }
Fn* トレイトには FnOnce, FnMut, Fn の三種類がある. この三種類には self の取り方の違いがあり, それぞれ self, &mut self, &self を取る. これらは次のように定義されていて, 継承関係がある.
pub trait Fn<Args> : FnMut<Args> { extern "rust-call" fn call(&self, args: Args) -> Self::Output; } pub trait FnMut<Args> : FnOnce<Args> { extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output; } pub trait FnOnce<Args> { type Output; extern "rust-call" fn call_once(self, args: Args) -> Self::Output; }
つまり, Fn トレイトを実装するには FnMut を実装しなければならないし, FnMut を実装するためには FnOnce を実装する必要があるということだ. 逆に, Fn トレイトが実装されていれば FnMut も FnOnce も実装されている.
Fn
Fn は環境を &self としてイミュータブルな参照として受け取る. すなわち, クロージャ内部で環境の値を読み取るだけのような場合に実装される.
ローカル変数のリンゴをキャプチャしてその重さを計るクロージャ scale を考えよう. 次のようになる。
struct Apple { weight: u32, } let apple = Apple { weight: 3 }; let scale = || { println!("the weight of apple: {}", apple.weight); }; scale();
このクロージャは環境にリンゴ apple を持つ. リンゴの重さを計るにはリンゴを改変する必要はない. だから scale の型は Fn トレイトを実装することができる (つまりそれが継承する FnMut も FnOnce も) .
Fn トレイトはなぜ FnMut を継承しているのか?
今はリンゴの重さを計りたい. これにはリンゴを改変する必要はない. だから「絶対つまみ食いをするなよ」と渡されても (Fn) 「リンゴをカットしてもいいよ」 (FnMut) と渡されても重さを計ることはできる. もしかしたらリンゴをカットした方が計りに載せやすい, ということはあるかもしれないが, そのままでも計れる. つまり FnMut は Fn より広い許可を与えることになり, Fn ならできたのに FnMut ではできない!ということにはならない.
FnMut
FnMut は環境を &mut self としてミュータブルな参照として受け取る. すなわち, クロージャ内部で環境の値を変更する必要がある場合に用いられる.
先のようにリンゴをカットするのでもよいが, ちょっとコードにできないので, リンゴをちょっと食べたいという例にしよう. 「少しリンゴを貸してくれ, ちょっと食べたら返すから」と, こう言うわけだ.
struct Apple { weight: u32, } let mut apple = Apple { weight: 3 }; let mut eat = || { // 全体の 3 分の 1 をちょっとと言うか否かは別問題 apple.weight -= 1; println!("the weight of apple: {}", apple.weight); }; eat();
apple を改変することなくしてリンゴを食べることはできないので, eat の型は Fn は実装できない. 自動的に FnMut 止まりとなる.
FnMut トレイトはなぜ FnOnce を継承しているのか?
Fn トレイトが FnMut を継承する理由と同様に考えることができる. 「リンゴちょっとなら食べてもいいけど返してね」 (FnMut) と言われるだけでできるなら, 「リンゴをまるごとあげるよ」 (FnOnce) と言われてもできる (むしろ後者の方が全部食べれて嬉しいかもしれない) .
FnOnce
FnOnce は環境を self として所有権ごともらいうける. 全てのクロージャが最低でも FnOnce は実装する. 実行できないクロージャは何なのか分からない.
食べた後のリンゴの種を回収して次のリンゴを育てたいとしよう (いや育たないだろうけど) . そのためには最後まで食べて種を回収する必要がある.
#[derive(Debug, Clone)] struct Seed; impl Seed { fn grow(self) -> Apple { Apple { weight: 4, seeds: vec![Seed; 3] } } } #[derive(Debug)] struct Apple { weight: u32, seeds: Vec<Seed> } let apple = Apple { weight: 3, seeds: vec![Seed; 4] }; let grow_apple = || { let seeds = apple.seeds.into_iter(); // 種回収 for seed in seeds { println!("{:?}", seed.grow()); // 育てる } }; grow_apple(); // 同じ種でもう一回育てようったって, そうはいかない // grow_apple();
grow_apple 内では種を回収している. そこまでするとリンゴの味見どころではない. そうするためにはリンゴごともらってしまう必要がある. 種回収しなきゃならないし. これでは FnOnce より先は実装できない.
なお FnOnce 関数は実行時に環境の所有権をとってしまうので二回目は実行できない. それが Once の由来だ.
まとめ
クロージャが環境に変数をキャプチャする方法には, & 借用, &mut 借用, 所有権ごとムーブの 3 通りがある. これらはクロージャの内部での使われ方により自動的に推論されるほか, move クロージャにすることでムーブを強制することもできる.
クロージャが実装するトレイトは 3 種類あり, 継承関係がある. どのトレイトまで実装するかはクロージャの内部での使われ方により自動的に推論される.
配列はポインタと同じものか
この記事は「こう考えたら自分なりに分かりやすかったな」というメモである. 実際の処理系の実装や実際の動作とは必ずしも一致しない.
配列とポインタの違いについて解説しているサイト ポインタ虎の巻~初期化文字列の2つの定義 を読んでいて面白かったので, 自分なりの理解をまとめた. 少し学んだ人ならすぐに気づくようなことなのかもしれないが.
通常, 配列名はその先頭要素のアドレスを指す. そのおかげで普段、型T []をもつ配列の 名前 をT *のように扱うことができる. 統一的に扱えるし, ポインタなら関数に渡すのも簡単. うまい仕組みだ.
では配列は, 実は先頭要素のアドレスを保持するポインタと等価なのか. 当然実際はそうではない. よく知られているように
char cha[4]; assert(&cha == cha);
は成功する. 型が違う (char (*)[4] <-> char *) ので警告は出るかもしれないが, 値は等しい. これはchaが通常のポインタならば有り得ない. &chaはそのポインタ変数そのもののアドレスになるからである.
ところで変数とは何か. 値を入れる箱である. では変数名とは何か. 入れる箱を識別するためのタグである. ではメモリの特定の領域に特定の名前がついていて, 名前でその領域にアクセスできるのか. そんなはずはない. メモリにはただ通し番号が振られているだけだ.
関数内で宣言したいわゆるローカル変数は, そのスタックフレームに領域を確保される. C言語関数辞典 - C言語用語集 スタックフレーム (stack frame) の図が見やすくて分かりやすい. コンパイラはローカル変数名とスタック上の位置を対応付けて持っている. あるローカル変数に対して読み書きするとき, コンパイラはその変数に対応する位置を取得して, 「取得した位置のメモリに対して読み書きするようなプログラム」を出力する. ここで変数名は消えさる. 出力されるプログラムはそのローカル変数の位置をベースポインタからの相対的距離で表しているわけだが, まあ, 実行段階なのでアドレスと同一視しよう.
変数名 -> アドレス -> 実体, という流れを踏む点で, 変数名によって実体を間接的に参照しているように見える. 通常の代入文では見えないので, ここでは見えない間接参照と呼ぼう. そして, アドレス演算子を使わなければ変数名に結び付いたアドレスを見ることはない. だから変数自体のアドレスのことを見えないアドレスと呼ぶことにする. 見えないアドレスとは呼んでも, 別に普通にアドレス演算子を適用すれば見えるのだが. つまり, 逆に言えばアドレス演算子は 見えない間接参照を抑制する 働きであるとも考えられる.
言ってることがよく分からないと思うので, たとえば次のような場合.
int c = 10; c; // (1) *(int *)0x1111; // (2)
値を捨てているが気にしない. 仮に &c == 0x1111 とする. (1) においてcを評価しているが, これは (2) と同値である. ユーザーは (1) の評価で明示的なデリファレンスも何もしないが, やってることはデリファレンスだと言いたかった. このデリファレンスを以って間接参照と呼んでいる.
話を戻す. 結論から言うと, 配列名が先頭アドレスになるという仕様は, いろいろな変数があるなかで配列名に限っては自動的にデリファレンスされないということだと理解できる. アドレス演算子を適用していないのに見えないアドレスが見えるということだ.
普通の変数名を評価するとその中身が返る. 先の例のように見えない間接参照をする. 単体の配列名が例外で, 見えない間接参照をしないのだ. そして見えないアドレスをそのまま返してくる. 逆に「Cで見えている世界」のうちで考えるなら, 何もしていないのにアドレス演算子を適用していると言い換えてもよい.
さて, ここまでくるとポインタとは根本的に違うものだと分かる. ポインタは, 所詮変数である. そのポインタ用に別途領域を確保し, その中身として何らかのアドレスを明示的に初期化あるいは代入する. ポインタ変数を評価すると, 見えない間接参照をして, ポインタ変数の中身を返す. 普通の変数と何の違いもない. でもたまたま型がアドレスを保持するためのものだったので, 評価結果はアドレスになる. それに対して配列名は, 見えない間接参照をしないで, つまり中身へ辿らず, そのまま見えないアドレスを返してくる.
ポインタのそれと違い配列の先頭アドレスを保存するための領域があるわけでもないし, その領域の値を間接参照しているわけでもない. 配列そのものに対して代入ができないのも納得である.
もう &cha == cha は簡単だ. まず右辺のchaは見えない間接参照を行わず見えないアドレスがそのまま出てくる. 左辺は, 配列名がアドレスに変換されるルールの例外で, ここでのchaは配列そのものだ. 少々ややこしいが, 配列そのものは普通の変数同様に見えない間接参照をすると みなせば どうだろうか. 具体的にどういうことだ... と考える必要はない. どうせアドレス演算子を適用するのである. 普通の変数と同様, アドレス演算子を適用した結果, 見えない間接参照が抑制され, 見えないアドレスがそのまま返るのだ. 結局, 右辺も左辺も同じになる.
おもしろい.